一、环境信息
NFS客户端:
银河麒麟V10,ARM架构
Linux version 4.19.90-24.4.v2101.ky10.aarch64
NFS服务器:
Windows Server 2022 Standard
二、问题现象
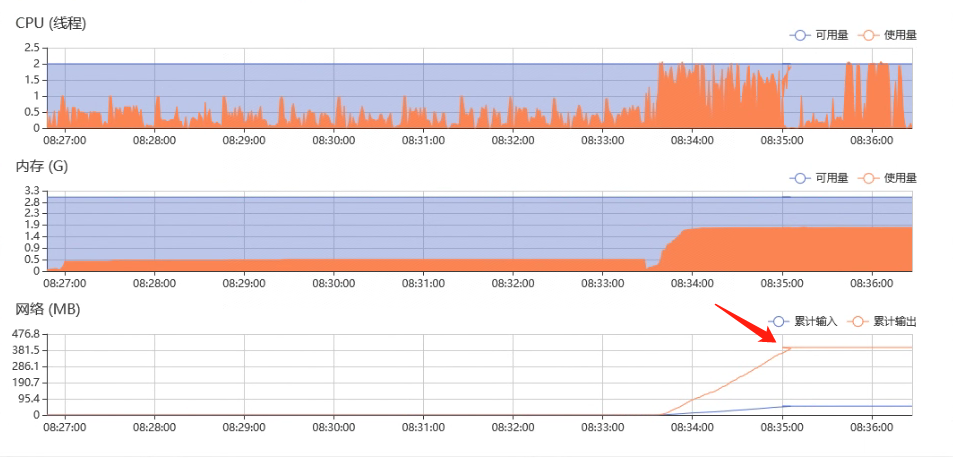
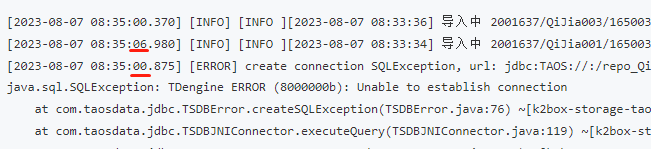
通过java api启动docker容器时发现容器没有起来,查询后台日志信息如下:
[2024-01-14 15:10:01.141] [INFO] Starting docker container
[2024-01-14 15:10:02.117] [INFO] Recoverable I/O exception (java.net.SocketException) caught when processing request to {}->http://192.168.101.80:22375
[2024-01-14 15:10:02.152] [INFO] Docker client connected successfully
[2024-01-14 15:10:07.154] [INFO] Recoverable I/O exception (java.net.SocketException) caught when processing request to {}->http://192.168.101.80:22375
[2024-01-14 15:10:07.220] [INFO] Docker client connected successfully
[2024-01-14 15:10:12.221] [INFO] Recoverable I/O exception (java.net.SocketException) caught when processing request to {}->http://192.168.101.80:22375
[2024-01-14 15:10:12.282] [INFO] Docker client connected successfully
[2024-01-14 15:10:17.284] [INFO] Recoverable I/O exception (java.net.SocketException) caught when processing request to {}->http://192.168.101.80:22375
[2024-01-14 15:10:17.354] [INFO] Docker client connected successfully
[2024-01-14 15:10:22.356] [INFO] Recoverable I/O exception (java.net.SocketException) caught when processing request to {}->http://192.168.101.80:22375
[2024-01-14 15:10:22.391] [INFO] Docker client connected successfully初步怀疑磁盘空间被占满导致,执行df命令时发现没有响应:
[root@192 storage]# df -h
(卡死在这里没有任何输出,只能按ctrl+c退出)三、问题解决
由于前几天出现过df命令无响应的情况,所以马上意识到可能是远程nfs挂载的远程磁盘有问题,经过询问果然是有人改了远程nfs服务器的ip地址。
让运维恢复了nfs服务器的地址,然后重启一下rpcbind服务:
systemctl restart rpcbind如果以上命令无效,可以尝试强制卸载nfs路径:
umount -f -l /mnt/hdfs/k2repos/CMSFTPServer此时df命令恢复正常:
[root@192 storage]# df -h | grep -v docker
Filesystem Size Used Avail Use% Mounted on
devtmpfs 32G 0 32G 0% /dev
tmpfs 32G 0 32G 0% /dev/shm
tmpfs 32G 546M 31G 2% /run
tmpfs 32G 0 32G 0% /sys/fs/cgroup
/dev/mapper/klas-root 4.0T 207G 3.8T 6% /
tmpfs 32G 0 32G 0% /tmp
/dev/vda2 1014M 218M 797M 22% /boot
/dev/vda1 599M 6.5M 593M 2% /boot/efi
192.168.101.251:/home/data 1022G 15G 1007G 2% /mnt/hdfs/k2repos
10.144.136.169:/CMSFTPServer 7.3T 6.1T 1.3T 83% /mnt/hdfs/k2repos/CMSFTPServer
tmpfs 6.3G 0 6.3G 0% /run/user/0日志显示java启动docker容器也恢复正常:
[2024-01-14 16:00:01.149] [INFO] Starting docker container
[2024-01-14 16:00:13.955] [INFO] Container started, status code: 1四、预防措施
为了预防类似情况发生时严重影响业务,可以考虑以soft模式挂载nfs服务(默认为hard模式),这样当nfs服务不可用时进程不会hang住,而是返回一个错误:
mount -o soft -t nfs 10.144.136.169:/CMSFTPServer /mnt/hdfs/k2repos/CMSFTPServer实测以soft模式启动后,若nfs服务不可用,docker容器能够正常启动,但此时df命令仍然无响应,此时用df -x nfs4命令可以查看除nfs以外的磁盘。
但soft模式也有代价:
Since nfsv4 performs open/lock operations that have their ordering strictly enforced by the server, the options intr and soft cannot be safely used. hard nfsv4 mounts are strongly recommended.
五、参考链接
- Common NFS Mount Options
- Can I use both soft and intr options for mounting a NFS CIFS drive? If yes, in which order?
- Is it possible to use df when some of the NFS disks are unresponsive?
- NFS mounts do not honor the 'intr' or 'nointr' mount options in RHEL 6 and later
- https://blog.csdn.net/cangpa3484/article/details/100955711