一、服务器配置
鲲鹏920(128核),512GB DDR4,SSD(原厂没有做RAID)
二、服务器环境测试结果
某项目的数据库使用DuckDB,其中有一个综合查询负载,此负载包含一个Select DISTINCT查询,50次Update操作,以及一个分页查询。
经测试发现此综合查询场景耗时比Apple M2笔记本长1 倍以上:
三、原因分析
1、CPU因素
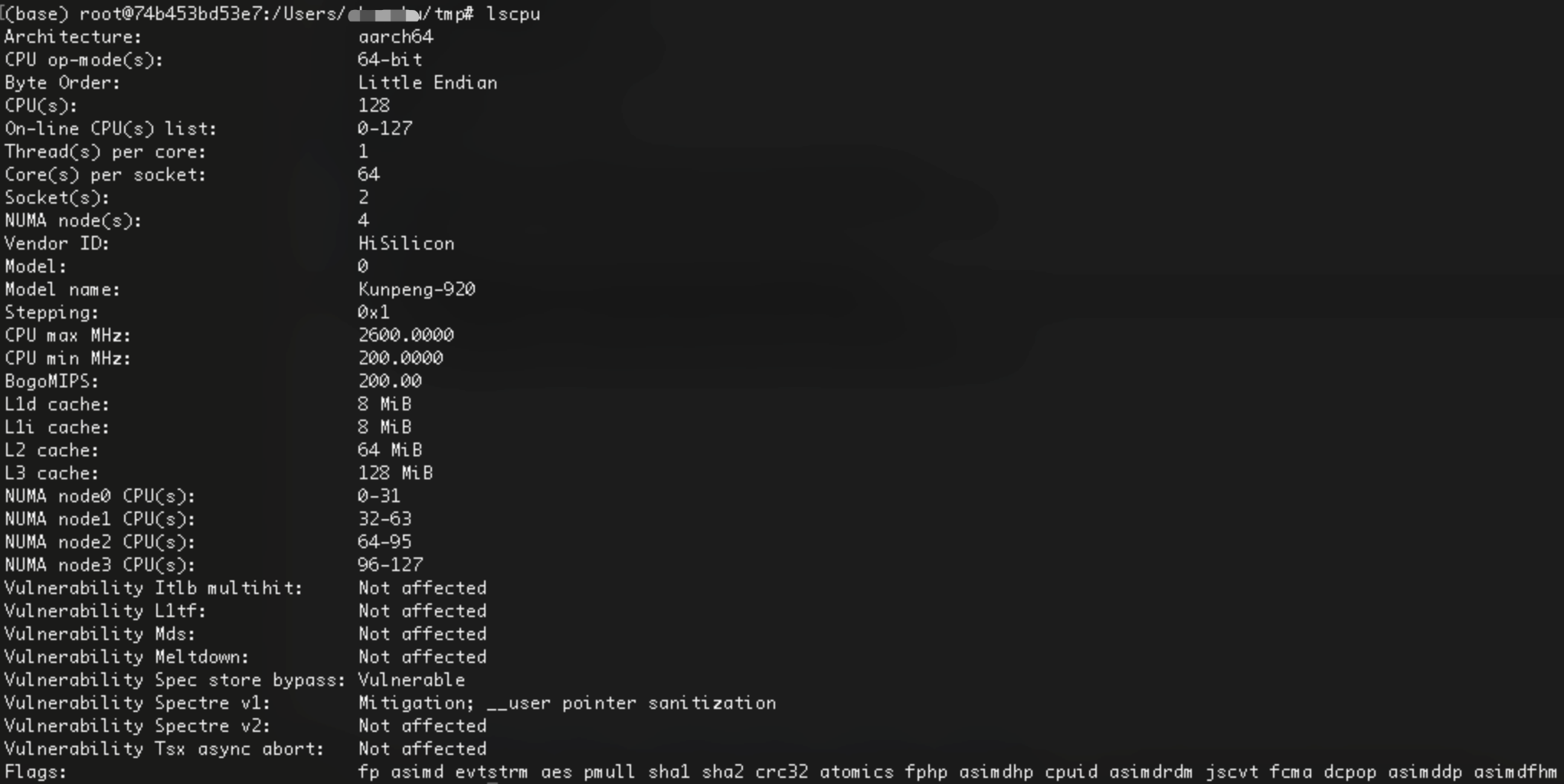
华为服务器虽然有128核,测试过程中用top命令观察CPU使用情况,实际利用的核数在4~60之间浮动,说明数据库(duckdb)已经利用了多核。
m2比服务器CPU频率快38%。
华为服务器:鲲鹏920 @2.6GHz,128-bit SIMD
m2笔记本:Apple M2 @3.6GHz
2、磁盘因素
m2与服务器都是SSD,前者比后者快43%。
测试命令:
fio --rw=readwrite --ioengine=sync --fdatasync=1 --directory=test-data --size=4g --bs=4k --name=mytest华为服务器:
read: IOPS=22.2k, BW=86.9MiB/s (91.1MB/s)(2049MiB/23590msec)
write: IOPS=22.2k, BW=86.8MiB/s (90.0MB/s)(2047MiB/23590msec)m2笔记本(256G SSD):
read: IOPS=31.6k, BW=123MiB/s (129MB/s)(2049MiB/16621msec)
write: IOPS=31.5k, BW=123MiB/s (129MB/s)(2047MiB/16621msec)3、内存因素
m2比服务器MEMCPY快4.8倍,MCBLOCK快1.6倍。
分析原因是服务器DDR4 3200MHz(鲲鹏920实际支持到2933MHz)频率低于m2笔记本的DDR5 6400MHz导致。
测试命令:
mbw -q -n 10 256华为服务器:
AVG Method: MEMCPY Elapsed: 0.05330 MiB: 256.00000 Copy: 4802.921 MiB/s
AVG Method: DUMB Elapsed: 0.04562 MiB: 256.00000 Copy: 5611.106 MiB/s
AVG Method: MCBLOCK Elapsed: 0.02116 MiB: 256.00000 Copy: 12099.614 MiB/sm2笔记本:
AVG Method: MEMCPY Elapsed: 0.00783 MiB: 256.00000 Copy: 32710.639 MiB/s
AVG Method: DUMB Elapsed: 0.01096 MiB: 256.00000 Copy: 23348.930 MiB/s
AVG Method: MCBLOCK Elapsed: 0.00800 MiB: 256.00000 Copy: 32016.809 MiB/s提高有效内存带宽:
用numactl -H命令看到鲲鹏920的128个核分布在4个numa node:
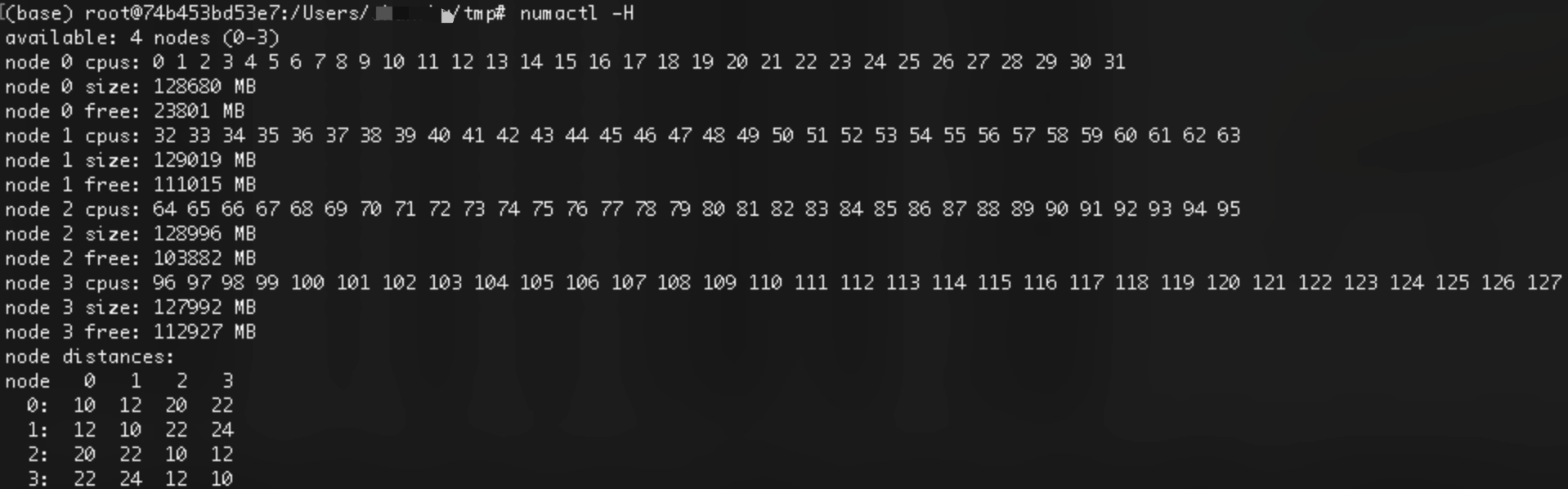
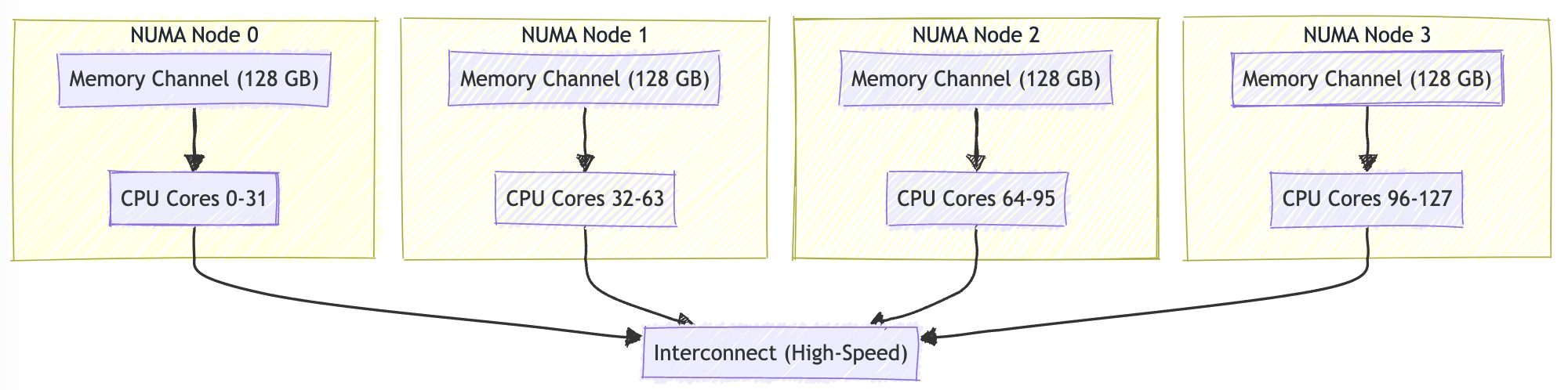
画成图就是这样的,CPU访问其他节点的内存时速度会受影响,影响程度取决于上图中的node distances数值:
用numactl -C 0-31命令可以将进程限制在node 0上,这样避免了跨node的cpu到内存访问延迟。例如用 numactl -C 0-31 mbw -q -n 10 256 命令再次测试内存带宽,可以看到MCBLOCK提高了接近1倍(但仍然显著低于m2笔记本),MCBLOCK通常用于需要高效传输大块数据的场景因此对内存带宽比较敏感:
华为服务器(0-31核):
AVG Method: MEMCPY Elapsed: 0.04889 MiB: 256.00000 Copy: 5236.255 MiB/s
AVG Method: DUMB Elapsed: 0.04096 MiB: 256.00000 Copy: 6249.985 MiB/s
AVG Method: MCBLOCK Elapsed: 0.01208 MiB: 256.00000 Copy: 21185.915 MiB/s四、改进
硬件方面服务器CPU无法更改,磁盘暂时无法更改(未来组RAID可提高性能),目前可以使用numactl提高有效内存带宽,测试查询性能是否有提高。
1、查询操作
经测试Select操作在所有核上运行与在0-31核运行,所消耗时间几乎相同。
2、更新操作
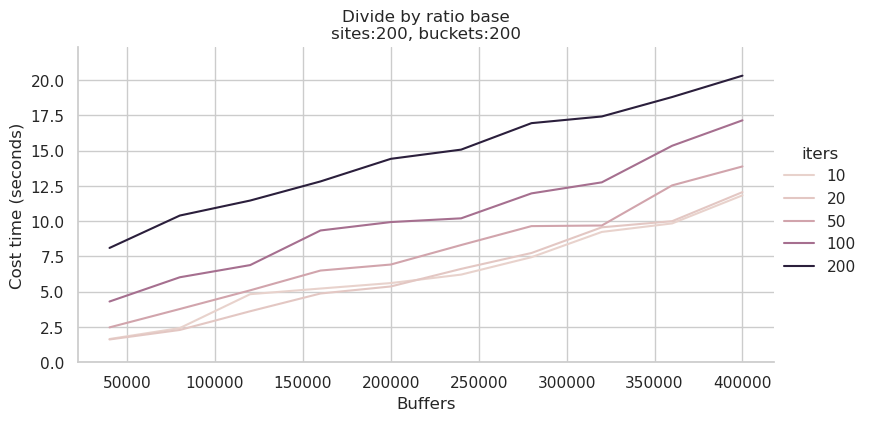
经测试发现Update操作对内存带宽比较敏感。上图为全部0-127核,下图为0-31核,可以看到后者消耗时间约为前者的70%~80%,性能提升还是比较明显的:
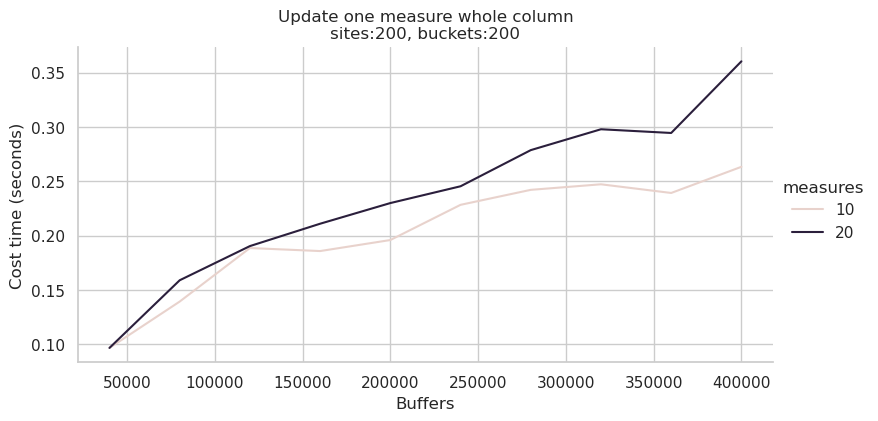
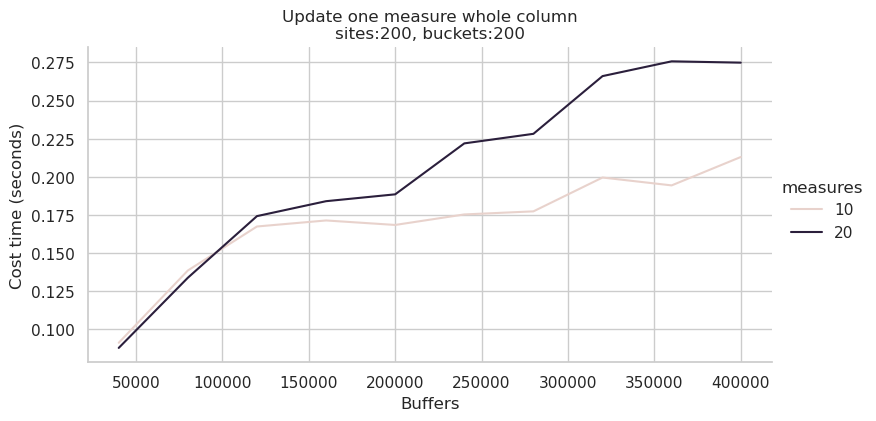
3、综合查询
用numactl -C 0-31方式运行综合查询测试,新的耗时大约是上次测试的 2/3,上图为全部0-127核,下图为0-31核:
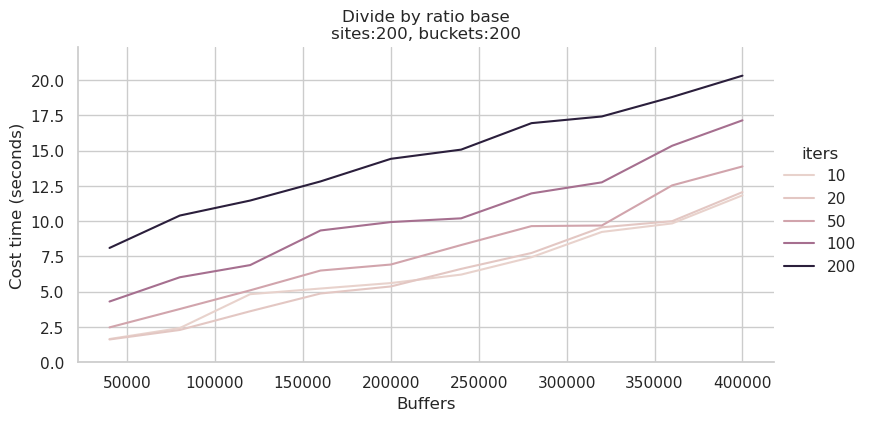
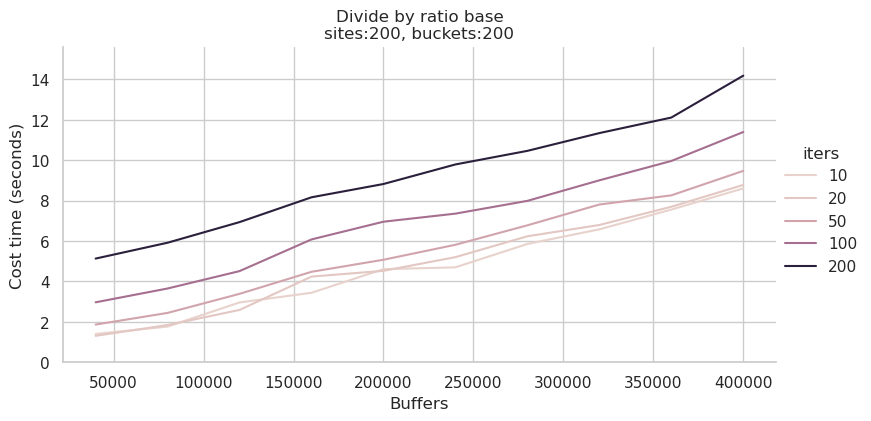
若使用64核运行测试,虽然CPU多了一倍,但耗时反而会增加20%左右,说明内存带宽对此负载的影响大于CPU核数的影响。
若使用16核运行测试,耗时介于比32核与64核之间。
五、附录
鲲鹏920 spec(非官方):https://ucfconsortium.org/wp-content/uploads/2020/02/Alex_Margolin_Kunpeng_UCX_Hackathon_2019.pdf
请保留原始链接:https://bjzhanghao.cn/p/3337