项目中遇到需要在离线环境下为anaconda安装python 3.8虚拟环境的问题,即服务器不能连接互联网的环境,这里记录一下解决方法。
一、环境信息
> uname -a
Linux taos-1 3.10.0-1160.el7.x86_64 #1 SMP Mon Oct 19 16:18:59 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
> conda --version
conda 4.5.4二、在线安装虚拟环境
如果已经有一个需要迁移的虚拟环境,则可以跳过这一步。
先找一台在线的服务器,安装anaconda所需的虚拟环境,我这里虚拟环境是python 3.8加上pandas、numpy和matplotlib等几个常用软件包。
> conda create -n python38 python=3.8
> conda install -n python38 pandas numpy matplotlib三、备份虚拟环境
使用conda pack命令完整备份虚拟环境:
> conda install -c conda-pack
> conda pack -n python38 -o env_python38_pack.tar.gz备份得到的是一个.tar.gz压缩包,如果查看压缩包里的内容,目录结构如下图所示:
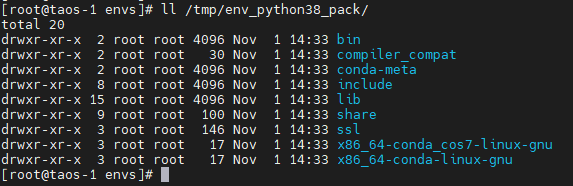
四、离线恢复虚拟环境
离线恢复不需要conda-pack命令,只需要将打好的虚拟环境包复制到目标环境的临时目录,然后解压缩到anaconda的envs目录下即可:
> mkdir /root/anaconda3/envs/python38
> tar zxvf /tmp/env_python38_pack.tar.gz -C /root/anaconda3/envs/python38输入conda info -e命令可以看到虚拟环境已经添加上了:
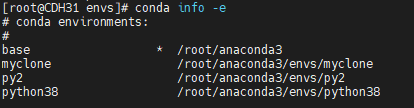
五、补充说明
1. 是否可以直接备份env下的目录?
一般不可以,按 conda-pack 官网给出的理由如下:
A tool like conda-pack is necessary because conda environments are not relocatable. Simply moving an environment to a different directory can render it partially or completely inoperable. conda-pack addresses this challenge by building archives from original conda package sources and reproducing conda’s own relocation logic.
网上有些文章提到可以直接备份envs/python38目录然后用下面的命令恢复:
> conda create -n [name] --clone [path] --offline但经过测试当虚拟环境有依赖包时,离线恢复环境会失败,提示下面的错误,原因可能是虚拟环境的依赖包与目标环境pkgs目录下的包版本不同:
RuntimeError('EnforceUnusedAdapter called with url https://repo.anaconda.com/pkgs/main/linux-64/ca-certificates-2022.10.11-h06a4308_0.tar.bz2\nThis command is using a remote connection in offline mode.\n',)
观察源anaconda下的pkgs目录可以发现,conda install安装新的虚拟环境时有一些依赖包是安装在pkgs目录下的。那么如果备份时将pkgs目录也备份下来是否可以呢?我认为有以下缺点:
pkgs目录比较大不方便网络传输(一般2GB~3GB);- 恢复时需要处理
envs和pkgs两个目录比较繁琐; - 对目标环境的侵入性比较高,因为会覆盖
pkgs下的一些文件。
如果只备份pkgs下的部分新安装的目录,比如按修改时间过滤,则可能遇到类似下面的错误:
FileNotFoundError: [Errno 2] No such file or directory: '/root/anaconda3/pkgs/libstdcxx-ng-11.2.0-h1234567_1/info/index.json'2. 是否可以用conda export命令备份?
如果目标环境是在线的可以用conda export命令备份,然后用conda create -f恢复。但对离线的情况不适用。
> conda env export -n python38 > /tmp/python38.yml
> cat /tmp/python38.yml
name: python38
channels:
- defaults
dependencies:
- ca-certificates=2022.10.11=h06a4308_0
- certifi=2022.9.24=py38h06a4308_0
- ld_impl_linux-64=2.38=h1181459_1
- libffi=3.3=he6710b0_2
- libgcc-ng=11.2.0=h1234567_1
- libstdcxx-ng=11.2.0=h1234567_1
- ncurses=6.3=h5eee18b_3
- openssl=1.1.1q=h7f8727e_0
- pip=22.2.2=py38h06a4308_0
- python=3.8.13=haa1d7c7_1
- readline=8.2=h5eee18b_0
- setuptools=65.5.0=py38h06a4308_0
- sqlite=3.39.3=h5082296_0
- tk=8.6.12=h1ccaba5_0
- wheel=0.37.1=pyhd3eb1b0_0
- xz=5.2.6=h5eee18b_0
- zlib=1.2.13=h5eee18b_0
prefix: /disk1/anaconda3/envs/python38
# 恢复环境
> conda env create -f python38.yaml综上,建议用conda pack命令备份anaconda的虚拟环境。
六、参考链接
https://www.anaconda.com/blog/moving-conda-environments
https://conda.github.io/conda-pack/
https://www.jianshu.com/p/adb927fa0091
https://blog.csdn.net/snowing118102/article/details/84319736
https://blog.csdn.net/CREATOR_Jay_xu/article/details/91971446


