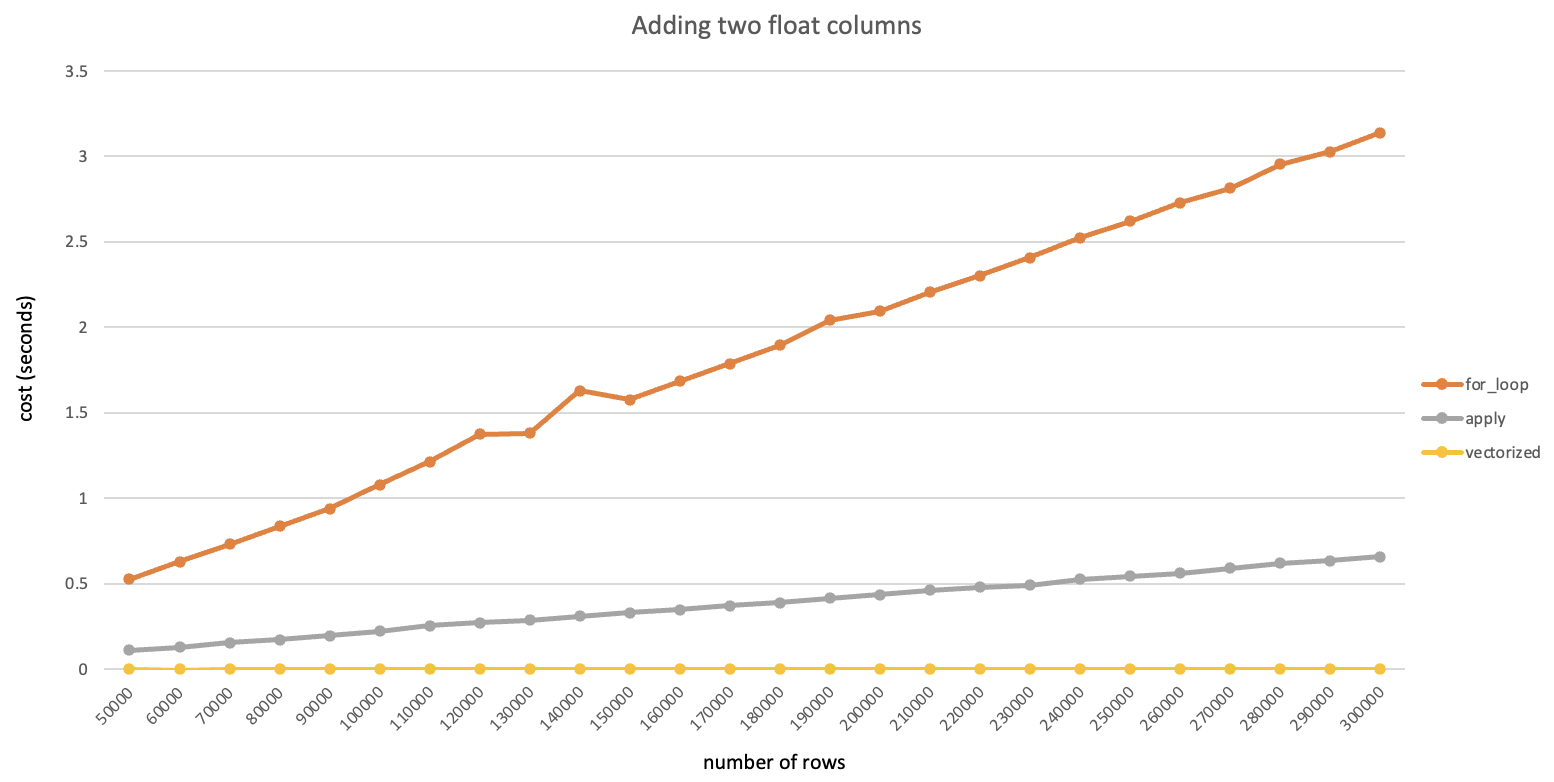
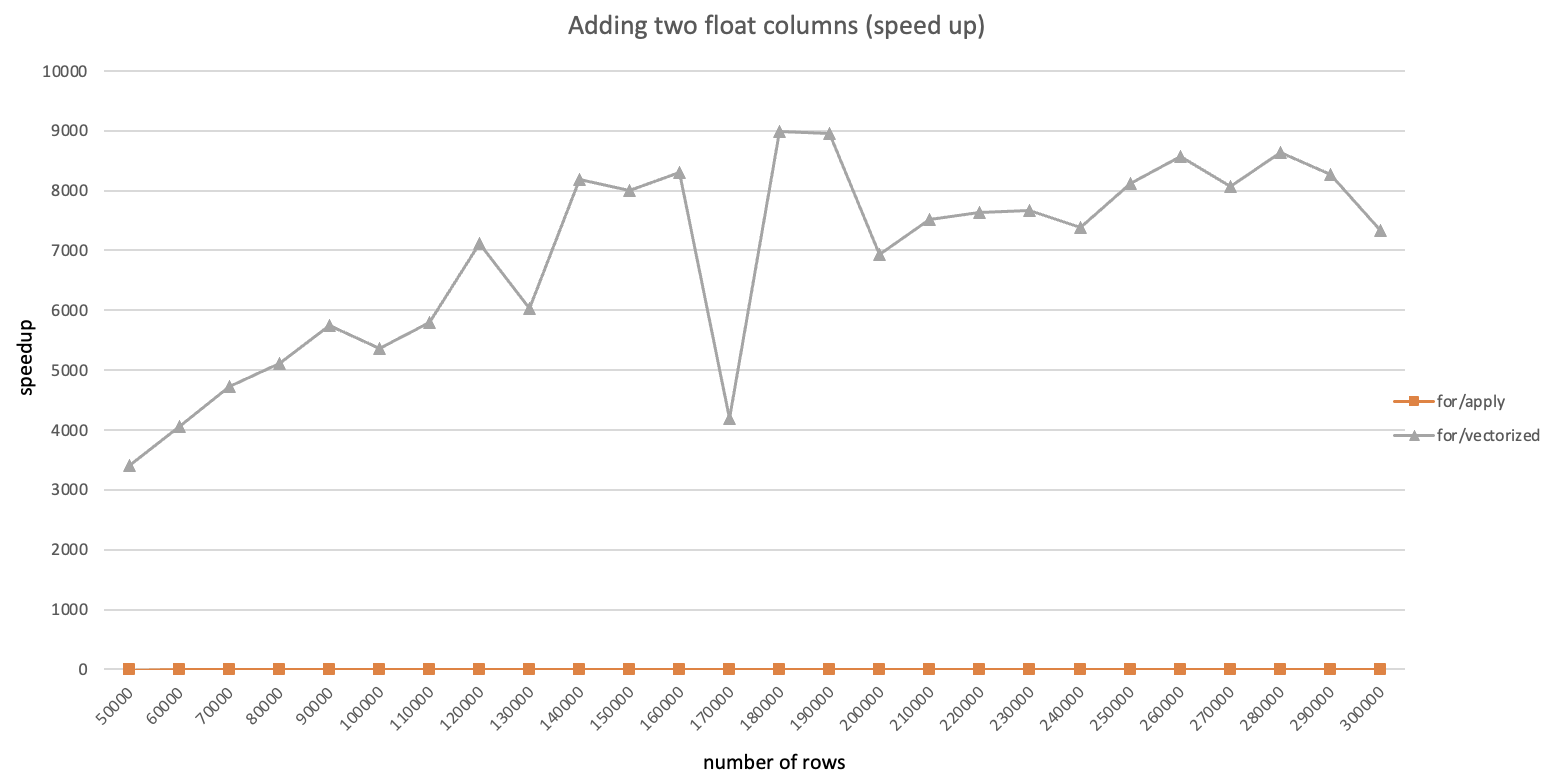
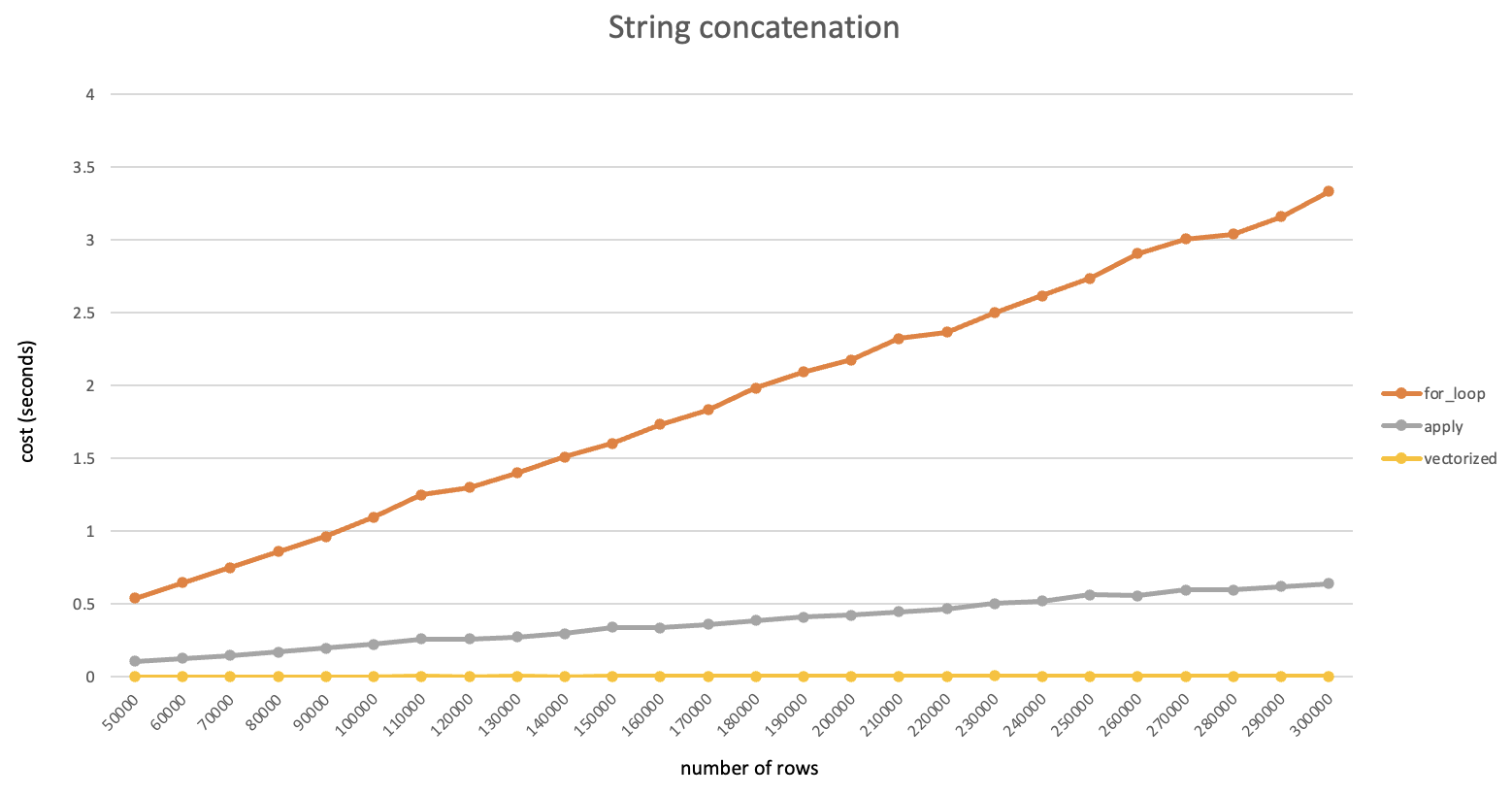
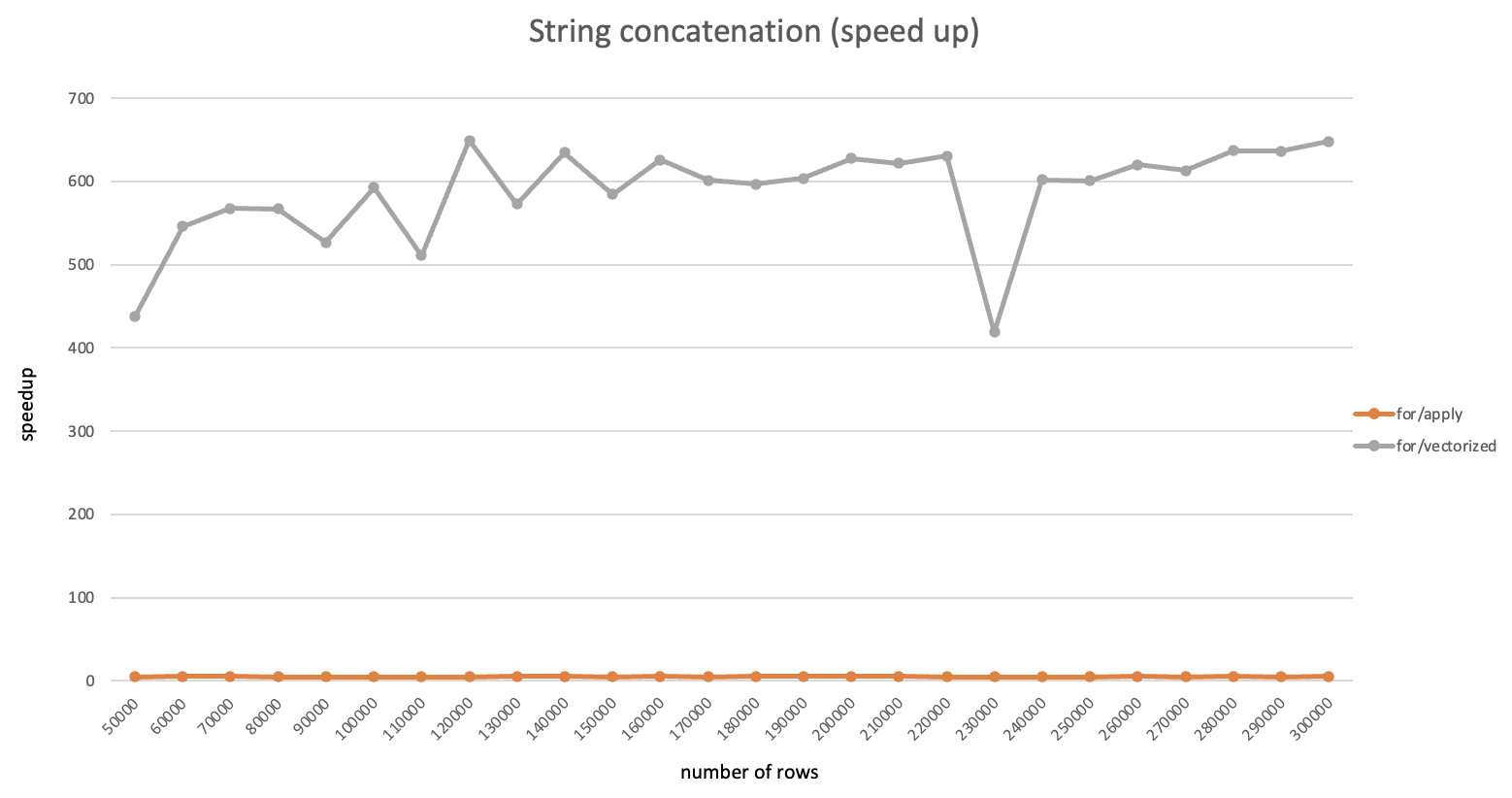
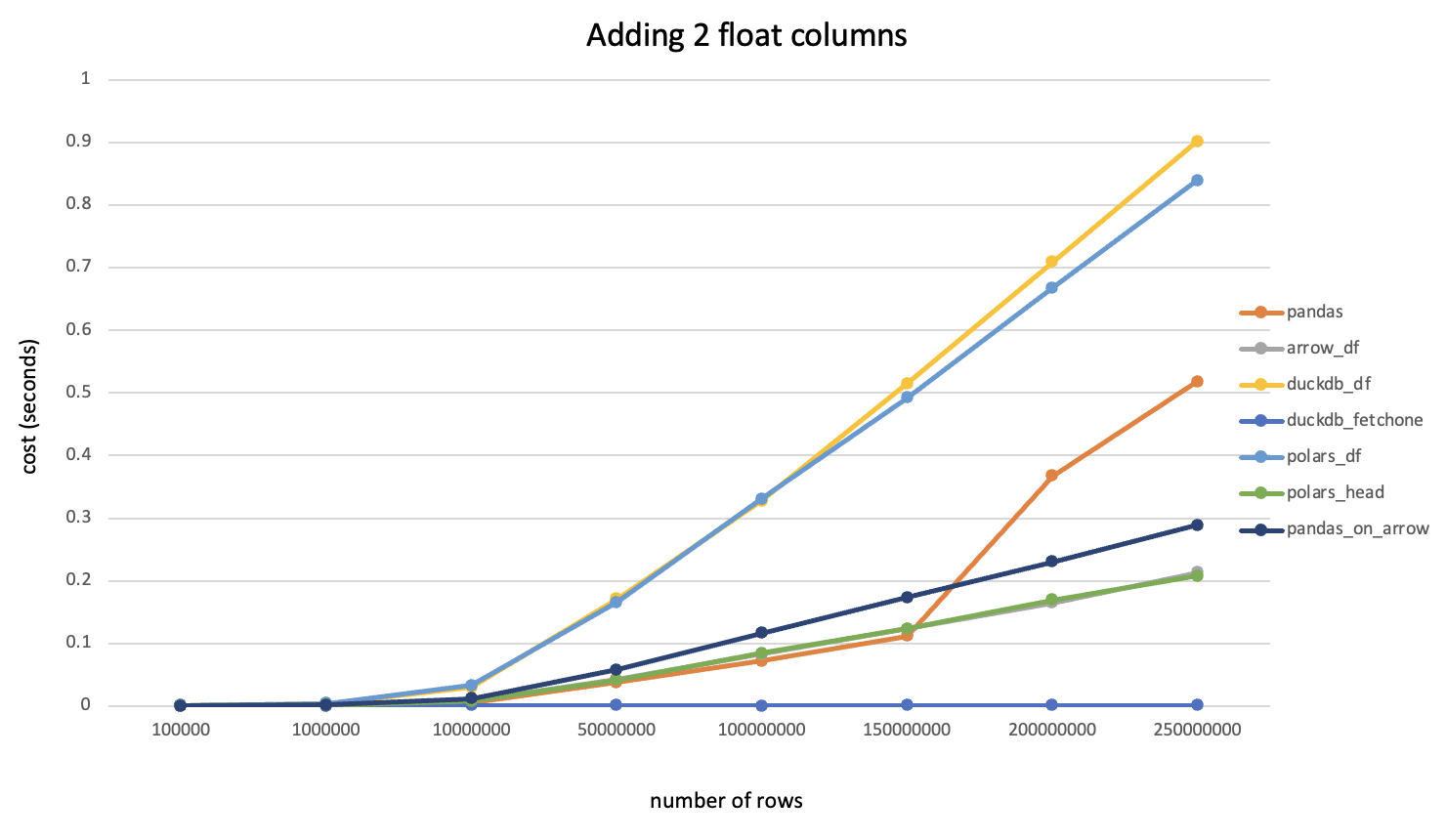
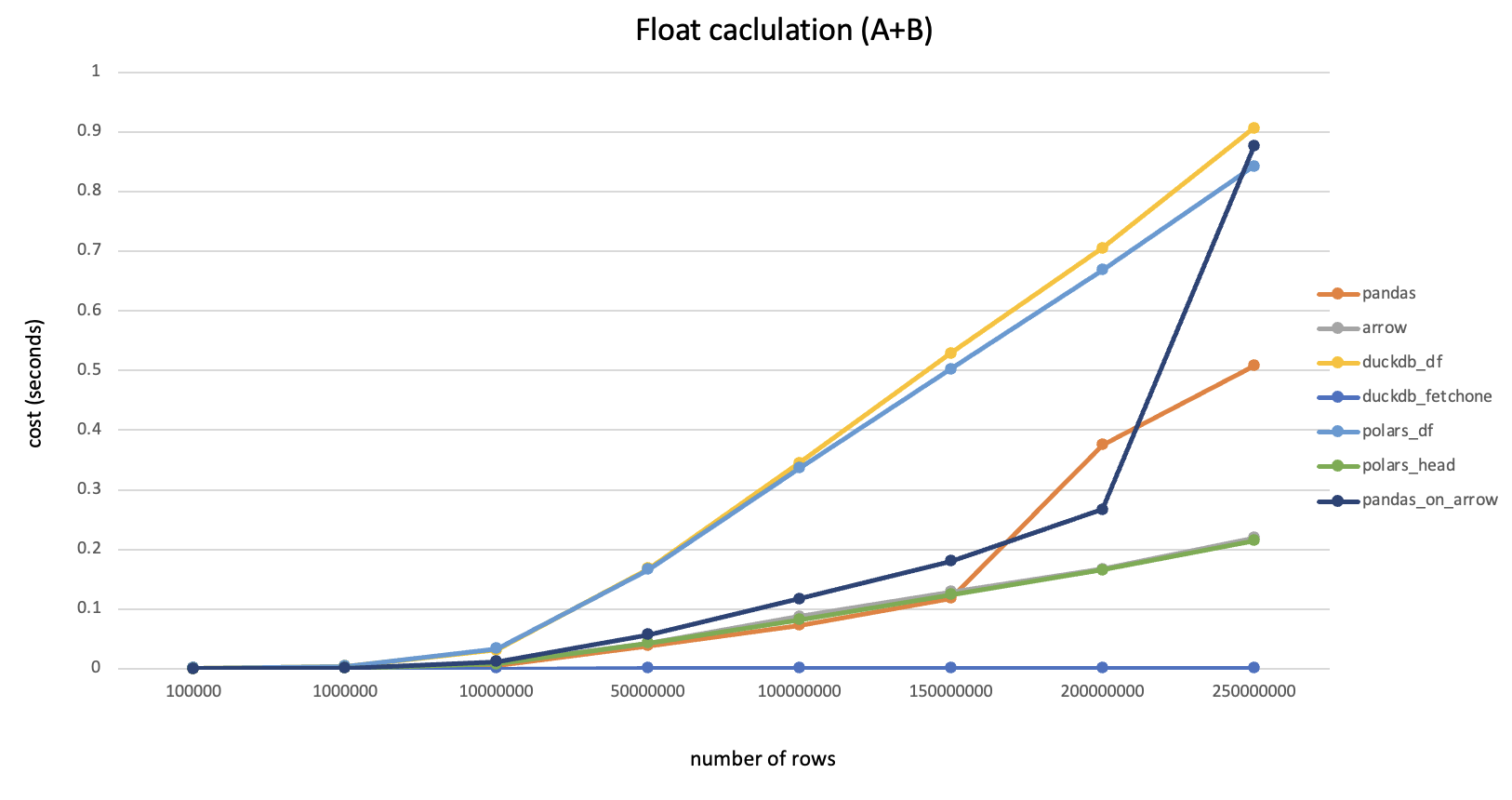
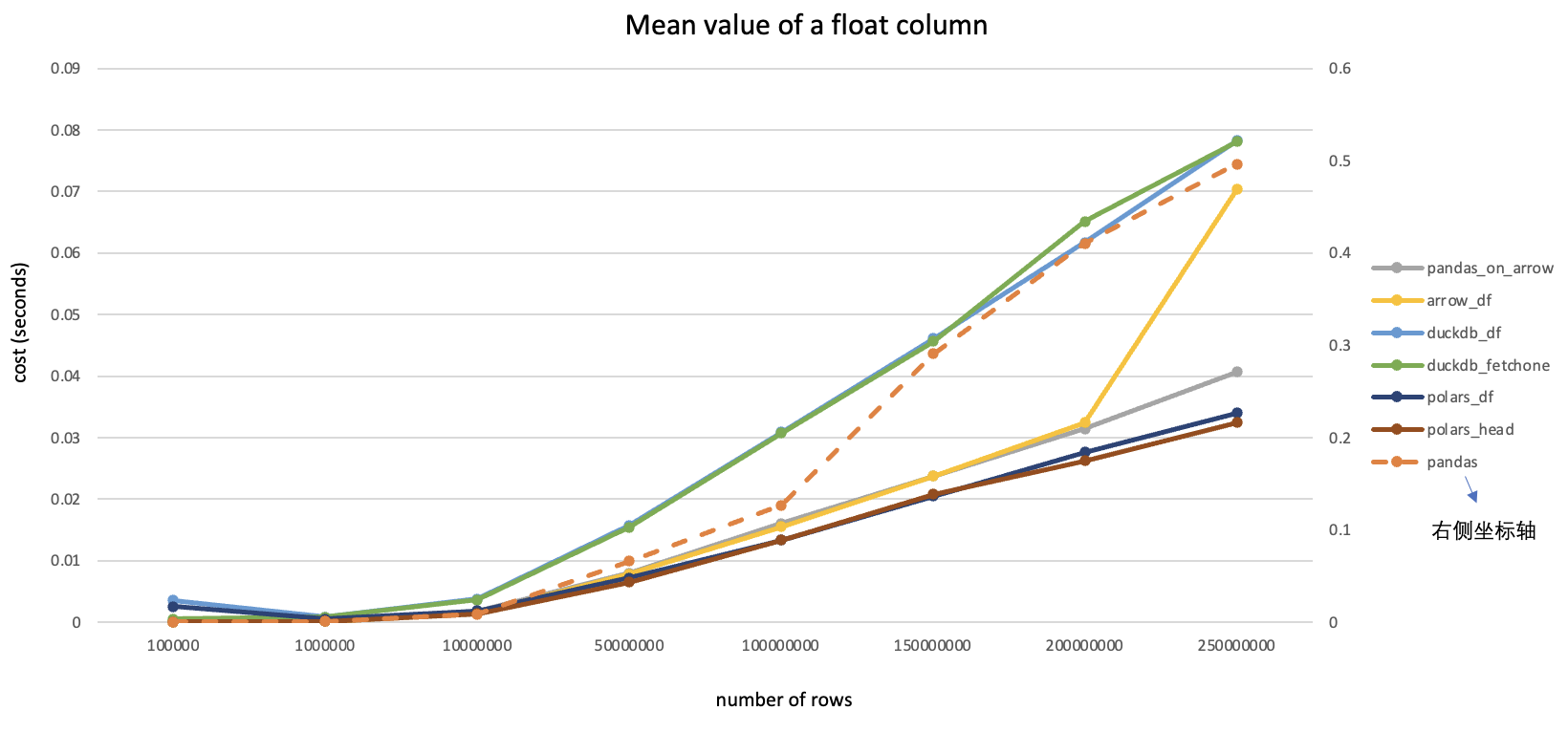
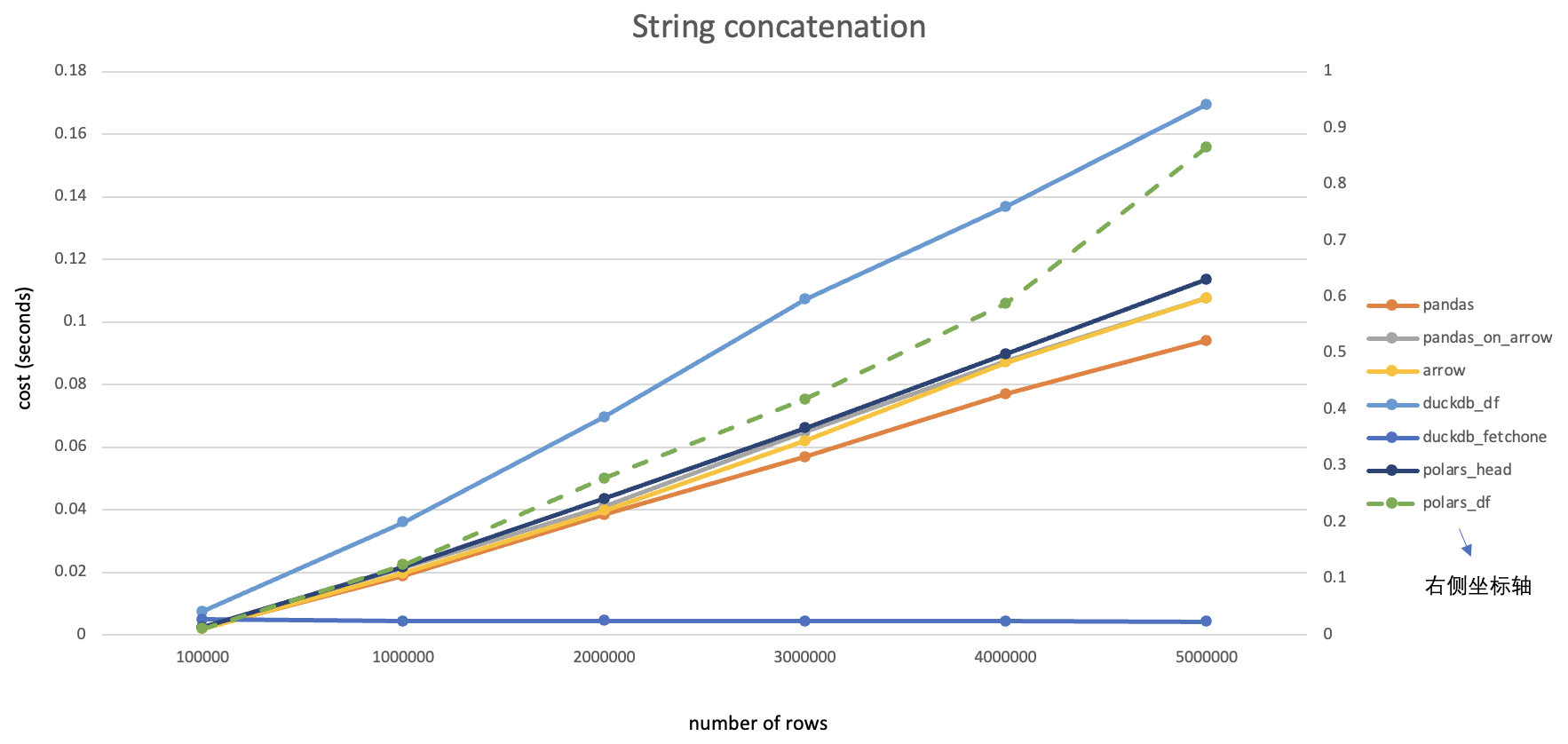
注:本文是一边安装一边记录形成的,其中有不少问题是由于centos版本较低导致的,建议使用高版本(>=7.6)安装以节约时间。
安装python
使用Anaconda管理环境
设置anaconda使用tuna(清华大学镜像):
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --set show_channel_urls yes
tuna还维护了一些第三方镜像,包括conda-forge, menpo等,需要的话也可以像上面这样添加,tuna页面有说明。
在conda环境里安装pytorch:
conda install pytorch-cpu -c pytorch
CUDA toolkit下载:https://developer.nvidia.com/accelerated-computing-toolkit
cuDNN下载:https://developer.nvidia.com/cudnn
用pip安装dlib(win下未成功,linux下没试):
从 https://pypi.org/simple/dlib/ 下载.whl格式的dlib,然后用pip安装:
pip install xxx.whl
用conda安装dlib:
用conda安装dlib(如果已经将menpo源添加到conda,则可以省略-c menpo选项):
conda install -c menpo dlib
conda提示Killed:
Update 201902: 另一个引发Killed的原因是内存不足,例如这台ec2上只有约300MB可用内存,经常出现Killed,增加512MB(总共800MB可用内存)后Killed的情况就少了很多。
这里遇到一个坑:用conda安装各种包时总报错“Killed”,网上也没找到类似问题,最后发现居然是磁盘空间满了,原来anaconda3居然占用了接近4GB的空间把硬盘填满了。另一个原因,需要conda update conda更新一下conda版本,之后就能正常安装了。
解决上述磁盘空间满问题后,发现conda install dlib时还会报错"Killed",加-vvv参数后发现可能与TUNA源有关:

从~/.condarc里删除相关TUNA源后问题即解决(应该主要是conda-forge这个镜像源的问题)。
偶尔还会遇到killed提示,但再试一次通常可以成功,因此猜测网络条件也会产生影响。
dlib与python版本:
在python 3.5环境里安装的dlib,虽然安装成功,但import dlib失败:
提示“ImportError: /root/miniconda3/envs/py35/lib/python3.5/site-packages/dlib.cpython-35m-x86_64-linux-gnu.so: undefined symbol: _PyThreadState_UncheckedGet”:

重新换python 3.6环境里安装dlib,可以import dlib成功:

升级glibc
由于是在centos6.5环境里,glibc版本比较低(2.12),而menpo源的dlib 19要求glibc 2.14,因此需要手工升级glibc。链接
安装必要的python库
conda install dlib -c menpo
conda install opencv -c menpo
conda install numpy
pip install imutils
如果安装opencv报内存不足(300MB剩余内存有此问题,700MB可以通过),可以尝试用pip安装opencv:
pip install opencv-python==3.4.1.15
Python编码问题
print()命令打印来自mysql的中文时报错如下:
UnicodeEncodeError: 'ascii' codec can't encode character '\xe9'
解决(绕过)方法:用logging.info()替代print()命令。
import logging
logging.basicConfig(level=logging.DEBUG,format='[%(levelname)s][%(asctime)s] %(message)s')
logging.info("my messages")
注意,默认logging输出到的是stderr而不是stdout。
一个简单的人脸检测程序
检测一张图片里的多个人脸,用绿色矩形标记并输出为图片。参考链接
from imutils import face_utils
import imutils
import dlib
import cv2
image = cv2.imread('/root/person01.jpg')
image = imutils.resize(image, width=500)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
detector = dlib.get_frontal_face_detector()
rects = detector(gray, 1)
for (i, rect) in enumerate(rects):
(x, y, w, h) = face_utils.rect_to_bb(rect)
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 1)
cv2.imwrite('/root/output.jpg',image)
python连接mysql数据库
过去常用的MySQLdb是c语言实现的,目前更建议使用MySQL官方提供的Connector/Python,是一个纯python的实现。
pip install mysql-connector-python
不过Connector/Python对mysql服务器版本有要求,例如2.0版以上就无法连接5.1版的mysql服务器,会报Bad Handshake错误。
另一个纯python的实现是PyMySQL,使用起来兼容性比较好。安装方法是:
pip install PyMySQL
用PyMySQL的一个简单例子:
import pymysql.cursors
cnx = pymysql.connect(user='xxx',password='xxx', host='localhost', database='xxx', charset='utf8mb4')
try:
with cnx.cursor() as cursor:
sql = "SELECT id, name, gender FROM user"
cursor.execute(sql)
for row in cursor:
print(row)
finally:
cnx.close()
安装tensorflow
tensorflow支持python3.5,所以用conda创建一个python 3.5环境后安装(参考链接):
conda create -n tensorflow python=3.5
source activate tensorflow
pip install tensorflow
如果是在centos 6上,由于自带的gcc是4.4.7版本过低,所以需要升级到gcc 4.8版本。直接下载编译的时间比较长(也比较容易遇到问题),可以使用devtools2辅助升级(参考链接):
wget http://people.centos.org/tru/devtools-2/devtools-2.repo -O /etc/yum.repos.d/devtools-2.repo
yum install devtoolset-2-gcc devtoolset-2-binutils devtoolset-2-gcc-c++
ln -s /opt/rh/devtoolset-2/root/usr/bin/* /usr/local/bin/
此时执行tensorflow程序可能会提示找不到库GLIBCXX_3.4.17的问题:
ImportError: /usr/lib64/libstdc++.so.6: version `GLIBCXX_3.4.17' not found (required by /root/miniconda3/envs/tensorflow/lib/python3.5/site-packages/tensorflow/python/_pywrap_tensorflow_internal.so)
此时可以从conda自带的lib目录里复制一个libstdc++.so.6.0.24版本并更新软连接解决:
cp /root/miniconda3/lib/libstdc++.so.6.0.24 /usr/lib64/
ln -s /usr/lib64/libstdc++.so.6.0.24 /usr/lib64/libstdc++.so.6
这时执行tensorflow程序遇到glibc版本过低的提示:
ImportError: /lib64/libc.so.6: version `GLIBC_2.16' not found
查看系统的glibc版本是2.14,因此需要升级。但是按照前述升级到glibc 2.14的方法(链接),升级为2.16时却遇到了下面的问题:
error while loading shared libraries: __vdso_time: invalid mode for dlopen(): Invalid argument
由于libc.so.6有问题,导致一些基本命令(例如rm)不可用,此时要切换回glibc 2.14的方法如下:
LD_PRELOAD=/opt/glibc-2.14/lib/libc-2.14.so rm -f /lib64/libc.so.6
LD_PRELOAD=/opt/glibc-2.14/lib/libc-2.14.so ln -s /opt/glibc-2.14/lib/libc-2.14.so /lib64/libc.so.6
原因(可能)是因为升级glibc时没有包含完整环境,使用下面的configure参数:
../configure --prefix=/opt/glibc-2.17 --disable-profile --enable-add-ons --with-headers=/usr/include --with-binutils=/usr/bin
上面命令有可能在check过程中出错(不支持--no-whole-archive),原因是binutils版本过低(2.23),需要升级到2.25,方法见链接。
升级binutils后虽然能够支持--no-whole-archive参数了,但升级glibc 2.16后的异常却没有任何变化。
至此,决定升级linux版本解决(从centos 6.5升级到7.6)。Update: 在centos 7.6下安装tensorflow十分顺利。
参考资料:
https://github.com/jcjohnson/pytorch-examples
Anaconda使用总结