对Linux服务器做基准测试可以帮助确定服务器在特定任务或负载下的性能。这不仅有助于我们了解服务器的处理能力、响应时间、吞吐量等关键性能指标,也有助于我们进行服务器容量规划,确保服务器在未来的工作负载下仍能保持良好的性能。
本文总结Linux下常用的基准测试工具的使用场景和方法,按硬件组成分为CPU、内存、磁盘和网络四个部分。其中有些工具不是Linux自带的,此时需要先安装工具。以fio为例,在Ubuntu里使用sudo apt-get install fio,在CentOS里则使用sudo yum install fio即可完成安装。
一、CPU基准测试
lscpu - 查看CPU硬件信息
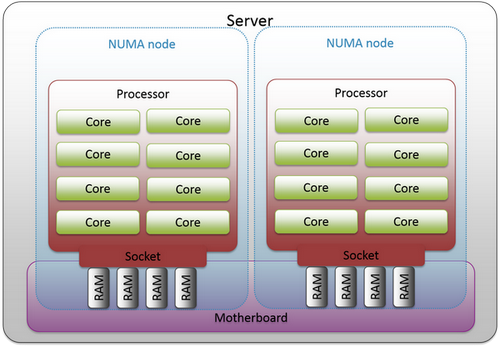
命令lscpu是显示关于 CPU 体系结构信息的一个工具,它从/proc/cpuinfo和其他系统文件中收集数据,汇总并以易于阅读的格式显示,不需要root权限。我们通常用它了解CPU的架构、核数和主频等基本信息:
> lscpu
Architecture: aarch64 <-- CPU架构,这里是ARM架构的
CPU op-mode(s): 64-bit
Byte Order: Little Endian
CPU(s): 128 <-- CPU核心数量128个
On-line CPU(s) list: 0-127
Thread(s) per core: 1 <-- 每核心线程数
Core(s) per socket: 64
Socket(s): 2 <-- 两个物理CPU插槽
NUMA node(s): 4 <-- NUMA节点数
Vendor ID: 0x48
Model: 0
Stepping: 0x1
CPU max MHz: 2600.0000 <-- CPU最大频率
CPU min MHz: 200.0000
BogoMIPS: 200.00
L1d cache: 8 MiB
L1i cache: 8 MiB
L2 cache: 64 MiB
L3 cache: 128 MiB <-- 三级缓存大小,此缓存是多核共享的
NUMA node0 CPU(s): 0-31
NUMA node1 CPU(s): 32-63
NUMA node2 CPU(s): 64-95
NUMA node3 CPU(s): 96-127
...
其中Core、Socket和NUMA node的概念可以参考下图(来源):
sysbench cpu - 测试CPU性能
使用sysbench工具可以测试CPU的实际性能,它内部是通过反复查找指定范围(默认10000)内所有素数实现的,每完整查找完成一次即为一个事件(event),默认10秒后输出平均每秒完成的事件次数(eps, events per second)作为衡量CPU性能的指标。
若测试时在命令行里添加--threads参数指定了多线程,则eps指标也会相应上升,简单公平起见我们都用默认单线程测试即可。
> sysbench cpu run
Prime numbers limit: 10000
Initializing worker threads...
Threads started!
CPU speed:
events per second: 3329.35 <-- 主要关注这个eps指标
General statistics:
total time: 10.0002s
total number of events: 33299
Latency (ms):
min: 0.30
avg: 0.30
max: 0.62
95th percentile: 0.31
sum: 9994.03
Threads fairness:
events (avg/stddev): 33299.0000/0.00
execution time (avg/stddev): 9.9940/0.00
二、内存基准测试
dmidecode - 查看内存条硬件信息
命令dmidecode从系统的 DMI(Desktop Management Interface)表中读取数据,提供关于系统硬件组件的详细信息,如 主板、BIOS、处理器、内存、缓存、芯片组和其他系统硬件的信息。我们通常用它查看主板上各个内存条的型号、容量、频率等硬件信息。
查看已安装的物理内存条数及容量:
> sudo dmidecode -t memory | grep 'GB'
Size: 32 GB <-- 单条内存容量32GB
Size: 32 GB
Size: 32 GB
Size: 32 GB
查看已安装的物理内存频率:
> sudo dmidecode -t memory | grep 'MT/s'
Speed: 3200 MT/s <-- 物理内存支持的最大频率
Configured Memory Speed: 2933 MT/s <-- 实际运行频率, 通常是CPU无法支持到内存最高频率导致的
Speed: 3200 MT/s
Configured Memory Speed: 2933 MT/s
Speed: 3200 MT/s
Configured Memory Speed: 2933 MT/s
Speed: 3200 MT/s
Configured Memory Speed: 2933 MT/s
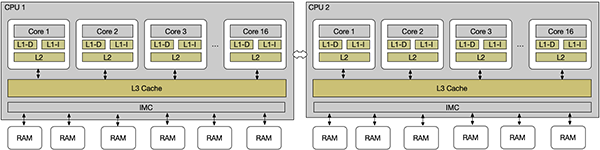
在测试内存性能时,需要注意缓存的影响,下图(来源)展示了典型的三级缓存架构。测试项目所处理的数据量应该大大超过缓存的大小,否则就变成了测试缓存的性能。
sysbench memory - 测试内存性能
用sysbench工具可以测试内存的实际性能:
> sysbench memory run
Running memory speed test with the following options:
block size: 1KiB
total size: 102400MiB
operation: write
scope: global
Initializing worker threads...
Threads started!
Total operations: 38967914 (3896177.52 per second)
38054.60 MiB transferred (3804.86 MiB/sec)
General statistics:
total time: 10.0002s
total number of events: 38967914
Latency (ms):
min: 0.00
avg: 0.00
max: 0.26
95th percentile: 0.00
sum: 4468.85
Threads fairness:
events (avg/stddev): 38967914.0000/0.00
execution time (avg/stddev): 4.4688/0.00
三、磁盘基准测试
lsblk - 查看磁盘信息
此命令可列出所有块设备及其属性,且不需要root权限。
> lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 446.6G 0 disk
├─sda1 8:1 0 512M 0 part /boot/efi
└─sda2 8:2 0 446.1G 0 part /
fdisk - 查看磁盘分区信息
命令fdisk是一个磁盘分区工具,也经常被用于显示磁盘信息,需要root权限。它比lsblk给出的信息更加详细一些,例如包含了每个磁盘分区的大小和文件系统信息。
> sudo fdisk -l
Disk /dev/sda: 446.64 GiB, 479559942144 bytes, 936640512 sectors
Disk model: SAS3908
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4096 bytes
I/O size (minimum/optimal): 262144 bytes / 262144 bytes
Disklabel type: gpt
Disk identifier: 6819FBA6-5719-44F1-A2B6-F444F542E8BC
Device Start End Sectors Size Type
/dev/sda1 2048 1050623 1048576 512M EFI System
/dev/sda2 1050624 936638463 935587840 446.1G Linux filesystem
fio - 测试磁盘性能
fio是一个专业的磁盘性能测试工具。它可以配置多种测试场景,包括顺序读写和随机读写等,我们主要关注IOPS(每秒操作数)和BW(带宽)指标。
以测试顺序读写性能为例:
> fio --rw=rw --directory=/tmp --size=256m --direct=1 --name=mytest
mytest: (g=0): rw=rw, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=psync, iodepth=1
fio-3.7
Starting 1 process
Jobs: 1 (f=1): [M(1)][100.0%][r=1749KiB/s,w=1789KiB/s][r=437,w=447 IOPS][eta 00m:00s]
mytest: (groupid=0, jobs=1): err= 0: pid=25055: Sun Jun 30 11:44:53 2024
...
Run status group 0 (all jobs):
READ: bw=1712KiB/s (1753kB/s), 1712KiB/s-1712KiB/s (1753kB/s-1753kB/s), io=128MiB (134MB), run=76476-76476msec
WRITE: bw=1716KiB/s (1757kB/s), 1716KiB/s-1716KiB/s (1757kB/s-1757kB/s), io=128MiB (134MB), run=76476-76476msec
命令行参数--direct表示是否使用操作系统级的磁盘缓存,默认值1。取0和1对结果影响很大(几十倍),0反映磁盘本身的性能,1更接近实际使用场景。
命令行参数--rw是指定要测试的项目,可选项是以下之一:
: read Sequential read
: write Sequential write
: trim Sequential trim
: randread Random read
: randwrite Random write
: randtrim Random trim
: rw Sequential read and write mix
: readwrite Sequential read and write mix
: randrw Random read and write mix
: trimwrite Trim and write mix, trims preceding writes
dd - 测试磁盘性能(仅顺序读写)
如果在服务器上无法安装fio等专业工具,可以用dd命令粗略测试磁盘的顺序读写性能,绝大部分linux发行版都自带dd命令,它本来的作用是快速复制和转换文件,不需要root权限。
凭空创建一个大小为 1GB 的文件 testfile,以此测量顺序写入的速度:
> dd if=/dev/zero of=/tmp/testfile bs=1G count=1 oflag=direct
1+0 records in
1+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.834568 s, 1.3 GB/s
从刚才创建的 testfile 中读取数据,以此测量顺序读取的速度:
> dd if=testfile of=/dev/null bs=1G count=1 iflag=direct
1+0 records in
1+0 records out
1073741824 bytes (1.1 GB, 1.0 GiB) copied, 0.665267 s, 1.6 GB/s
四、网络基准测试
lspci - 查看网卡硬件信息
用Linux自带的lspci命令可以查看所有pci设备的基本信息,我们用ethernet过滤一下就可以得到网卡信息,例如网卡型号。此命令不需要root权限。
> lspci | grep -i ethernet
7d:00.0 Ethernet controller: Huawei Technologies Co., Ltd. HNS GE/10GE/25GE RDMA Network Controller (rev 21)
7d:00.1 Ethernet controller: Huawei Technologies Co., Ltd. HNS GE/10GE/25GE Network Controller (rev 21)
7d:00.2 Ethernet controller: Huawei Technologies Co., Ltd. HNS GE/10GE/25GE RDMA Network Controller (rev 21)
7d:00.3 Ethernet controller: Huawei Technologies Co., Ltd. HNS GE/10GE/25GE Network Controller (rev 21)
更详细的信息可以加-v参数获得:
> lspci -v | grep -i ethernet -A 10
7d:00.0 Ethernet controller: Huawei Technologies Co., Ltd. HNS GE/10GE/25GE RDMA Network Controller (rev 21)
Subsystem: Huawei Technologies Co., Ltd. HNS GE/10GE/25GE RDMA Network Controller
Flags: bus master, fast devsel, latency 0, NUMA node 0
Memory at 121000000 (64-bit, prefetchable) [size=64K]
Memory at 120000000 (64-bit, prefetchable) [size=1M]
Capabilities: <access denied> <-- 要显示全部能力需要加sudo
Kernel driver in use: hns3
Kernel modules: hclge, hns3, hns_roce_hw_v2
...
不过lspci命令无法看到网卡的MAC地址,为解决这个问题我们可以使用ifconfig命令或ip命令。
ip -查看MAC地址和IP地址
以前我们经常使用ifconfig命令查看mac地址和ip地址,但这个工具已经几乎停止开发,逐渐被新的ip命令取代。因此这里我们仅介绍后者的使用方法。
注:有些Linux发行版已经不再默认提供ifconfig,若一定要使用,请先安装net-tools组件,例如sudo apt-get install net-tools。
使用ip addr命令可以查看mac地址和ip地址。在下面的例子里,网卡1是LoopBack接口用于与本机通讯,网卡2~4为没有接入网络的物理网卡(DOWN),网卡5为已接入网络的网卡(UP)
> ip addr
ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: enp125s0f0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether c0:4e:f6:5d:24:06 brd ff:ff:ff:ff:ff:ff
3: enp125s0f1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether c0:4e:f6:5d:24:07 brd ff:ff:ff:ff:ff:ff
4: enp125s0f2: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether c0:4e:f6:5d:24:08 brd ff:ff:ff:ff:ff:ff
5: enp125s0f3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether c0:4e:f6:5d:24:09 brd ff:ff:ff:ff:ff:ff <-- MAC地址
inet 192.168.1.6/16 brd 192.168.255.255 scope global enp125s0f3 <-- IP地址、广播地址
valid_lft forever preferred_lft forever
inet6 fe80::b24f:a6ff:fe5c:1409/64 scope link
valid_lft forever preferred_lft forever
ip命令还有很多功能,例如ip link set可以修改网卡属性,ip route可以操作静态路由表等,限于篇幅这里不作展开了。
netperf - 测试网络性能
使用 netperf 测试网络性能需要两台服务器,一台以netserver命令启动服务端(默认端口12865):
> sudo netserver -4 -L 0.0.0.0 -p 9292
Starting netserver with host '0.0.0.0' port '9292' and family AF_INET
另一台作为客户端以netperf命令向服务端反复发送数据,下面的例子中-t TCP_CRR表示为每次交易建立一个新的tcp连接(http的场景),-r 4k,1k指定请求和响应内容的大小,-l 30指定测试时长为30秒:
> netperf -H 127.0.0.1 -P 9292 -l 30 -t TCP_CRR -- -r 4k,1k
MIGRATED TCP Connect/Request/Response TEST from 0.0.0.0 (0.0.0.0) port 0 AF_INET to 127.0.0.1 () port 0 AF_INET : demo
Local /Remote
Socket Size Request Resp. Elapsed Trans.
Send Recv Size Size Time Rate
bytes Bytes bytes bytes secs. per sec
16384 131072 4000 1000 30.00 10808.27 <-- 每秒完成10808个请求响应
16384 131072