服务器重启后zookeeper启动失败,报错日志如下:
zookeeper | ZooKeeper JMX enabled by default
zookeeper | Using config: /opt/zookeeper-3.4.13/bin/../conf/zoo.cfg
zookeeper | 2022-10-05 17:24:53,976 [myid:] - INFO [main:QuorumPeerConfig@136] - Reading configuration from: /opt/zookeeper-3.4.13/bin/../conf/zoo.cfg
zookeeper | 2022-10-05 17:24:53,979 [myid:] - INFO [main:DatadirCleanupManager@78] - autopurge.snapRetainCount set to 3
zookeeper | 2022-10-05 17:24:53,979 [myid:] - INFO [main:DatadirCleanupManager@79] - autopurge.purgeInterval set to 1
zookeeper | 2022-10-05 17:24:53,980 [myid:] - WARN [main:QuorumPeerMain@116] - Either no config or no quorum defined in config, running in standalone mode
zookeeper | 2022-10-05 17:24:53,980 [myid:] - INFO [PurgeTask:DatadirCleanupManager$PurgeTask@138] - Purge task started.
zookeeper | 2022-10-05 17:24:53,990 [myid:] - INFO [main:QuorumPeerConfig@136] - Reading configuration from: /opt/zookeeper-3.4.13/bin/../conf/zoo.cfg
zookeeper | 2022-10-05 17:24:53,990 [myid:] - INFO [main:ZooKeeperServerMain@98] - Starting server
zookeeper | 2022-10-05 17:24:53,995 [myid:] - INFO [main:Environment@100] - Server environment:zookeeper.version=3.4.13-2d71af4dbe22557fda74f9a9b4309b15a7487f03, built on 06/29/2018 04:05 GMT
zookeeper | 2022-10-05 17:24:53,996 [myid:] - INFO [main:Environment@100] - Server environment:host.name=fdf9214b4b7e
zookeeper | 2022-10-05 17:24:53,996 [myid:] - INFO [main:Environment@100] - Server environment:java.version=1.7.0_65
zookeeper | 2022-10-05 17:24:53,996 [myid:] - INFO [main:Environment@100] - Server environment:java.vendor=Oracle Corporation
zookeeper | 2022-10-05 17:24:53,996 [myid:] - INFO [main:Environment@100] - Server environment:java.home=/usr/lib/jvm/java-7-openjdk-amd64/jre
zookeeper | 2022-10-05 17:24:53,996 [myid:] - INFO [main:Environment@100] - Server environment:java.class.path=/opt/zookeeper-3.4.13/bin/../build/classes:/opt/zookeeper-3.4.13/bin/../build/lib/*.jar:/opt/zookeeper-3.4.13/bin/../lib/slf4j-log4j12-1.7.25.jar:/opt/zookeeper-3.4.13/bin/../lib/slf4j-api-1.7.25.jar:/opt/zookeeper-3.4.13/bin/../lib/netty-3.10.6.Final.jar:/opt/zookeeper-3.4.13/bin/../lib/log4j-1.2.17.jar:/opt/zookeeper-3.4.13/bin/../lib/jline-0.9.94.jar:/opt/zookeeper-3.4.13/bin/../lib/audience-annotations-0.5.0.jar:/opt/zookeeper-3.4.13/bin/../zookeeper-3.4.13.jar:/opt/zookeeper-3.4.13/bin/../src/java/lib/*.jar:/opt/zookeeper-3.4.13/bin/../conf:
zookeeper | 2022-10-05 17:24:53,996 [myid:] - INFO [main:Environment@100] - Server environment:java.library.path=/usr/java/packages/lib/amd64:/usr/lib/x86_64-linux-gnu/jni:/lib/x86_64-linux-gnu:/usr/lib/x86_64-linux-gnu:/usr/lib/jni:/lib:/usr/lib
zookeeper | 2022-10-05 17:24:53,996 [myid:] - INFO [main:Environment@100] - Server environment:java.io.tmpdir=/tmp
zookeeper | 2022-10-05 17:24:53,996 [myid:] - INFO [main:Environment@100] - Server environment:java.compiler=<NA>
zookeeper | 2022-10-05 17:24:53,998 [myid:] - INFO [main:Environment@100] - Server environment:os.name=Linux
zookeeper | 2022-10-05 17:24:53,998 [myid:] - INFO [main:Environment@100] - Server environment:os.arch=amd64
zookeeper | 2022-10-05 17:24:53,998 [myid:] - INFO [main:Environment@100] - Server environment:os.version=4.4.249-1.el7.elrepo.x86_64
zookeeper | 2022-10-05 17:24:53,998 [myid:] - INFO [main:Environment@100] - Server environment:user.name=root
zookeeper | 2022-10-05 17:24:53,999 [myid:] - INFO [main:Environment@100] - Server environment:user.home=/root
zookeeper | 2022-10-05 17:24:53,999 [myid:] - INFO [main:Environment@100] - Server environment:user.dir=/opt/zookeeper-3.4.13
zookeeper | 2022-10-05 17:24:54,000 [myid:] - INFO [PurgeTask:DatadirCleanupManager$PurgeTask@144] - Purge task completed.
zookeeper | 2022-10-05 17:24:54,000 [myid:] - INFO [main:ZooKeeperServer@836] - tickTime set to 2000
zookeeper | 2022-10-05 17:24:54,000 [myid:] - INFO [main:ZooKeeperServer@845] - minSessionTimeout set to -1
zookeeper | 2022-10-05 17:24:54,000 [myid:] - INFO [main:ZooKeeperServer@854] - maxSessionTimeout set to -1
zookeeper | 2022-10-05 17:24:54,007 [myid:] - INFO [main:ServerCnxnFactory@117] - Using org.apache.zookeeper.server.NIOServerCnxnFactory as server connection factory
zookeeper | 2022-10-05 17:24:54,010 [myid:] - INFO [main:NIOServerCnxnFactory@89] - binding to port 0.0.0.0/0.0.0.0:2181
zookeeper | 2022-10-05 17:24:54,799 [myid:] - ERROR [main:ZooKeeperServerMain@66] - Unexpected exception, exiting abnormally
zookeeper | java.io.EOFException
zookeeper | at java.io.DataInputStream.readInt(DataInputStream.java:392)
zookeeper | at org.apache.jute.BinaryInputArchive.readInt(BinaryInputArchive.java:63)
zookeeper | at org.apache.zookeeper.server.persistence.FileHeader.deserialize(FileHeader.java:66)
zookeeper | at org.apache.zookeeper.server.persistence.FileTxnLog$FileTxnIterator.inStreamCreated(FileTxnLog.java:585)
zookeeper | at org.apache.zookeeper.server.persistence.FileTxnLog$FileTxnIterator.createInputArchive(FileTxnLog.java:604)
zookeeper | at org.apache.zookeeper.server.persistence.FileTxnLog$FileTxnIterator.goToNextLog(FileTxnLog.java:570)
zookeeper | at org.apache.zookeeper.server.persistence.FileTxnLog$FileTxnIterator.next(FileTxnLog.java:650)
zookeeper | at org.apache.zookeeper.server.persistence.FileTxnSnapLog.fastForwardFromEdits(FileTxnSnapLog.java:219)
zookeeper | at org.apache.zookeeper.server.persistence.FileTxnSnapLog.restore(FileTxnSnapLog.java:176)
zookeeper | at org.apache.zookeeper.server.ZKDatabase.loadDataBase(ZKDatabase.java:217)
zookeeper | at org.apache.zookeeper.server.ZooKeeperServer.loadData(ZooKeeperServer.java:284)
zookeeper | at org.apache.zookeeper.server.ZooKeeperServer.startdata(ZooKeeperServer.java:407)一开始怀疑是zoo.cfg损坏,但查看后发现文件没有明显异常。将/opt/zookeeper-3.4.13/data/version-2目录改名为version-2.bak后重启zookeeper正常(但client连接报错 zxid 0x02 our last zxid is 0x0 client must try another server,因为前面的操作导致zk这边的事务id被重置了),说明可能是data下有文件损坏。
进一步查看version-2.bak下的文件,发现有一个0字节的log文件:
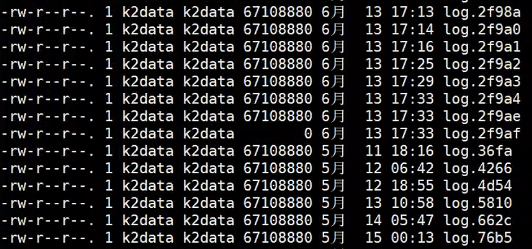
删除此文件并将version-2.bak改回原来的名字version-2,重启zookeeper成功,并且client连接正常。