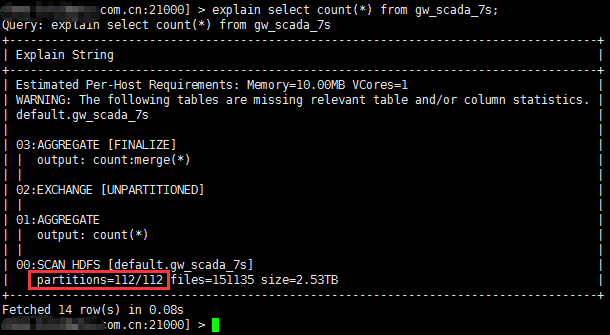
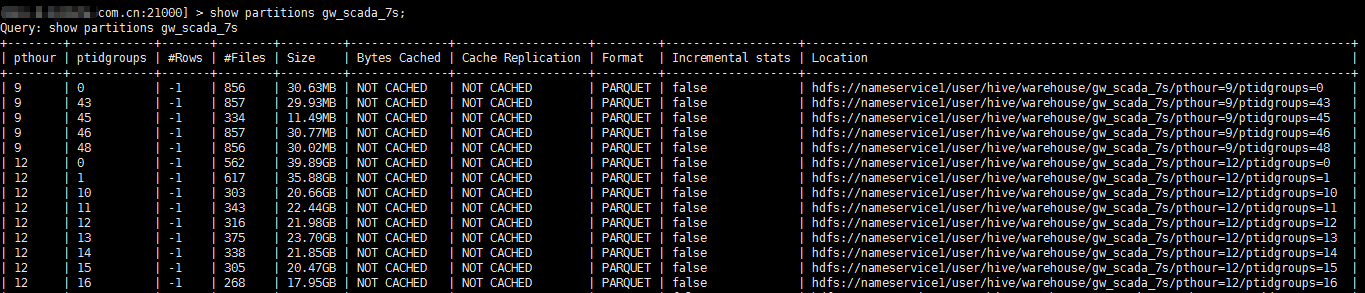
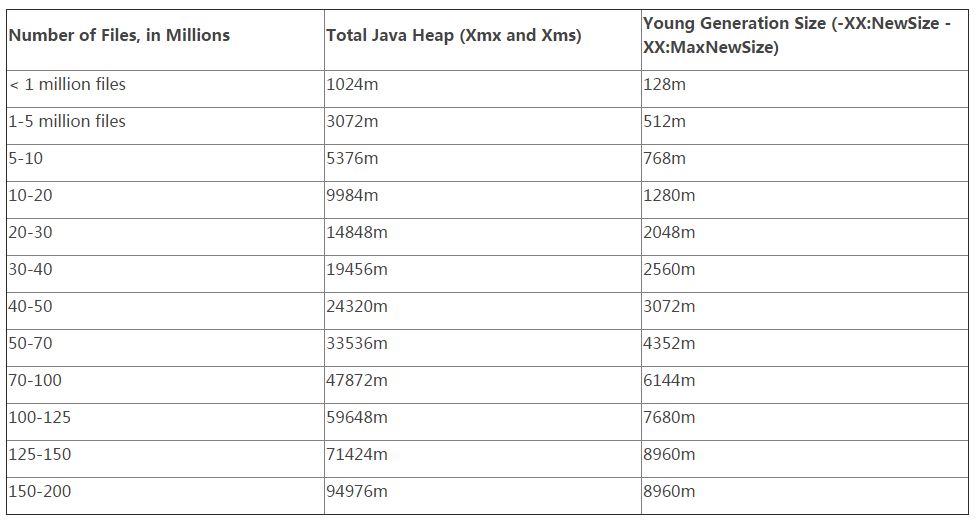
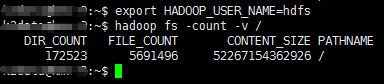
Apache Parquet是大数据平台里广泛使用的一种开源的列式文件存储格式,MapReduce和Spark等计算框架都内置了对读写Parquet文件的支持,通常Parquet文件放在HDFS上使用。
有时我们需要用Java直接读写本地的Parquet文件,在没有MapReduce或Spark等工具的情况下,要实现读写Parquet文件可以借助hadoop-client和parquet-hadoop这两个包实现。
一、依赖类库
首先需要在Java工程的pom.xml里添加下面的依赖项(引入hadoop-client会显著增大fat jar包的体积,但目前没有很好的替代方案):
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-hadoop</artifactId>
<version>1.10.1</version>
</dependency>二、将数据写入Parquet文件
Parquet官方提供了org.apache.parquet.example.data.Group作为一条记录的对象,这里演示以此对象写入parquet文件的方法。为了简化示例代码,parquet文件里每一列的类型都使用整型。
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.parquet.example.data.Group;
import org.apache.parquet.example.data.simple.SimpleGroupFactory;
import org.apache.parquet.hadoop.ParquetWriter;
import org.apache.parquet.hadoop.example.GroupWriteSupport;
import org.apache.parquet.hadoop.metadata.CompressionCodecName;
import org.apache.parquet.schema.*;
import java.io.IOException;
/**
* 示例程序:数据以 org.apache.parquet.example.data.Group 的形式写入Parquet文件
*/
public class WriteParquetDemoGroup {
Configuration conf;
public WriteParquetDemoGroup() {
conf = new Configuration();
conf.set("fs.hdfs.impl",
org.apache.hadoop.hdfs.DistributedFileSystem.class.getName()
);
conf.set("fs.file.impl",
org.apache.hadoop.fs.LocalFileSystem.class.getName()
);
}
public void writeParquet(int numRows, String[] fields, Path parquetPath) throws IOException {
Types.MessageTypeBuilder schemaBuilder = Types.buildMessage();
for (int j = 0; j < fields.length; j++) {
schemaBuilder.addField(new PrimitiveType(Type.Repetition.REQUIRED, PrimitiveType.PrimitiveTypeName.INT32, fields[j]));
}
MessageType schema = schemaBuilder.named("record");
GroupWriteSupport.setSchema(schema, conf);
GroupWriteSupport writeSupport = new GroupWriteSupport();
writeSupport.init(conf);
ParquetWriter<Group> writer = null;
try {
writer = new ParquetWriter<Group>(parquetPath,
writeSupport,
CompressionCodecName.SNAPPY,
ParquetWriter.DEFAULT_BLOCK_SIZE, ParquetWriter.DEFAULT_PAGE_SIZE, ParquetWriter.DEFAULT_PAGE_SIZE,
ParquetWriter.DEFAULT_IS_DICTIONARY_ENABLED,
ParquetWriter.DEFAULT_IS_VALIDATING_ENABLED,
ParquetWriter.DEFAULT_WRITER_VERSION,
conf);
for (int i = 0; i < numRows; i++) {
Group group = new SimpleGroupFactory(schema).newGroup();
for (int j = 0; j < fields.length; j++) {
group.add(fields[j], i * j);
}
writer.write(group);
}
} catch (IOException e) {
e.printStackTrace();
} finally {
if (writer != null) {
try {
writer.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}三、从Parquet文件读取数据
读取Parquet文件的代码本身很简单,只是要特别注意一点,为了能发挥Parquet列式存储的优势,应将要读取的列配置到PARQUET_READ_SCHEMA参数,以便跳过其他不需要扫描的列,从而提高读取性能。
public void readParquetWithReadSchema(Path parquetPath, String[] queryFields) throws IOException {
// 将要读取的列配置到PARQUET_READ_SCHEMA,如果缺失这一步读取性能将严重降低
Types.MessageTypeBuilder builder = Types.buildMessage();
for (int j = 0; j < queryFields.length; j++) {
builder.addField(new PrimitiveType(Type.Repetition.REQUIRED, PrimitiveType.PrimitiveTypeName.INT32, queryFields[j]));
}
MessageType messageType = builder.named("record");
conf.set(ReadSupport.PARQUET_READ_SCHEMA, messageType.toString());
// 读取Parquet文件
GroupReadSupport readSupport = new GroupReadSupport();
ParquetReader.Builder<Group> readerBuilder = ParquetReader.builder(readSupport, parquetPath);
ParquetReader<Group> reader = readerBuilder.withConf(conf).build();
Group line = null;
while ((line = reader.read()) != null) {
for (String field : queryFields) {
line.getInteger(field, 0);
}
}
}四、性能测试
写了一个简单的测试用例ParquetDemoTest,验证不同条件下上面的代码写入和读取Parquet文件的耗时。运行环境是普通笔记本电脑,i5 CPU + SSD硬盘。
写入性能:固定每行500列,可以看到写入parquet文件的耗时与写入的行数成正比;
读取性能:从parquet文件中读取少量列时速度是很快的,读取耗时与读取的列数成正比;
错误读取:当没有配置PARQUET_READ_SCHEMA时,读取多少列耗时都与读取500列差不多,未能体现列式存储的优势。
写入Parquet文件(Group), 100 行 x 500 列, 耗时 1580 ms
写入Parquet文件(Group), 500 行 x 500 列, 耗时 6927 ms
写入Parquet文件(Group), 1000 行 x 500 列, 耗时 12424 ms
写入Parquet文件(Group), 2000 行 x 500 列, 耗时 25849 ms
写入Parquet文件(Group), 3000 行 x 500 列, 耗时 36799 ms
读取Parquet文件(过滤列), 3000 行 x 5 列, 耗时 180 ms
读取Parquet文件(过滤列), 3000 行 x 10 列, 耗时 202 ms
读取Parquet文件(过滤列), 3000 行 x 15 列, 耗时 171 ms
读取Parquet文件(过滤列), 3000 行 x 50 列, 耗时 258 ms
读取Parquet文件(过滤列), 3000 行 x 100 列, 耗时 504 ms
读取Parquet文件(过滤列), 3000 行 x 200 列, 耗时 1608 ms
读取Parquet文件(过滤列), 3000 行 x 300 列, 耗时 2544 ms
读取Parquet文件(过滤列), 3000 行 x 400 列, 耗时 3998 ms
读取Parquet文件(过滤列), 3000 行 x 500 列, 耗时 6022 ms
读取Parquet文件(未过滤列), 3000 行 x 5 列, 耗时 6188 ms
读取Parquet文件(未过滤列), 3000 行 x 5 列, 耗时 6795 ms
读取Parquet文件(未过滤列), 3000 行 x 10 列, 耗时 6717 ms
读取Parquet文件(未过滤列), 3000 行 x 15 列, 耗时 6268 ms
读取Parquet文件(未过滤列), 3000 行 x 50 列, 耗时 6311 ms
读取Parquet文件(未过滤列), 3000 行 x 100 列, 耗时 7317 ms
读取Parquet文件(未过滤列), 3000 行 x 200 列, 耗时 6637 ms
读取Parquet文件(未过滤列), 3000 行 x 300 列, 耗时 6676 ms
读取Parquet文件(未过滤列), 3000 行 x 400 列, 耗时 7225 ms
读取Parquet文件(未过滤列), 3000 行 x 500 列, 耗时 6928 ms五、代码下载
文中使用的代码:parquet-demo-1.0.0-src.zip