Spark从1.2版开始提供了被称为Spark SQL Data Sources API的扩展机制,允许用户将任意形式的数据对接到Spark作为数据源,在Spark里可以用统一的方式访问这些数据。
All of the scheduling and execution in Spark is done based on these methods, allowing each RDD to implement its own way of computing itself. Indeed, users can implement custom RDDs (e.g. for reading data from a new storage system) by overriding these functions. Please refer to the Spark paper for more details on RDD internals.
HBase Spark Connector就是HBase官方提供的这样一个数据源的实现,相当于Spark与HBase之间的桥梁(见下图)。本文介绍如何安装、配置和在Spark中使用此连接器。为节约篇幅,本文中将HBase Spark Connector简称为hsc。
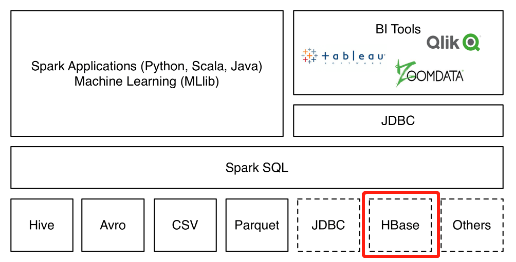
注意,在github上还有一个名为Spark Hbase Connector的项目,简称shc,是Hortonworks提供的,此项目最后commit停在2020年1月,而hsc截至2022年12月仍有新的代码在提交。因此更推荐使用hsc而不是shc。
环境信息
| HBase | Spark | PySpark | Hadoop | Maven | 操作系统 |
|---|---|---|---|---|---|
| 2.5.1 集群版 | 3.1.3 | 3.1.3 | 3.2.3 | 3.8.2 | CentOS 7.9 |
获取hsc
首先从github下载项目代码,按项目README.md里给出的mvn命令按指定版本编译:
> git clone https://github.com/apache/hbase-connectors.git
> cd hbase-connectors/spark/hbase-spark
> mvn -Dspark.version=3.1.3 -Dscala.version=2.12.10 -Dhadoop-three.version=3.2.3 -Dscala.binary.version=2.12 -Dhbase.version=2.5.1 clean install编译成功后将得到三个jar文件(hbase-spark.jar、hbase-spark-protocol-shaded.jar和scala-library.jar),按本文环境编译的jar包可以点击下载,如果你的环境版本正好相同可直接使用。
配置hsc
仍然是按项目README.md里的说明配置即可。
客户端配置:
将hbase-site.xml复制到 $SPARK_CONF_DIR 目录下。
服务端配置:
将前面编译得到的三个jar文件复制到hbase region-server安装目录下的lib目录下:
[root@taos-2 lib]# ll /usr/local/hbase-2.5.1/lib
-rw-r--r-- 1 root root 508987 May 30 17:09 hbase-spark-1.0.1-SNAPSHOT.jar
-rw-r--r-- 1 root root 40374 May 30 17:09 hbase-spark-protocol-shaded-1.0.1-SNAPSHOT.jar
-rw-r--r-- 1 root root 5276900 May 30 16:58 scala-library-2.12.10.jar在PySpark里读取HBase数据
我们直接在python命令行里进行验证(python环境需要已经安装与spark版本相同的pyspark)。
> python3
>>> from pyspark.sql import SparkSession
>>> from pyspark.sql import SQLContext
>>> import pandas as pd
>>> spark = SparkSession.builder.getOrCreate()
>>> sqlContext = SQLContext(spark.sparkContext)
>>> df = sqlContext.read.format( 'org.apache.hadoop.hbase.spark')\
.option('hbase.table','table1')\
.option('hbase.columns.mapping','rowKey String :key, col1 String cf1:col1, col2 String cf2:col2')\
.option("hbase.spark.use.hbasecontext", False)\
.load()
>>> df.show(2,False)
+----------------------+--------------------------+-----------------------------------------------+
|col1 |col2 |rowKey |
+----------------------+--------------------------+-----------------------------------------------+
|{"dq":65012,"cq":3189}|{"stac":1,"ndc":3,"mdc":0}|005e6c9b-d843-4e7c-9fa0-77fe894e42f7_1662393625|
|{"dq":65012,"cq":3189}|{"stac":1,"ndc":3,"mdc":0}|005e6c9b-d843-4e7c-9fa0-77fe894e42f7_1662393686|
+----------------------+--------------------------+-----------------------------------------------+
only showing top 2 rows至此通过hsc读取hbase数据已经验证通过。上述python命令也可以保存为.py文件,使用spark-submit命令提交。
> spark-submit --name xxx --master yarn --deploy-mode client spark_hbase_example.py关于Partition
从hsc代码的HBaseTableScanRDD.scala的实现可以看出,hsc对DataFrame的partition划分是根据hbase region的数量来的,因此如果region数量不合理,就可能需要对DataFrame进行repartition处理从而带来额外的shuffle开销。
@InterfaceAudience.Private
class HBaseTableScanRDD(relation: HBaseRelation,
val hbaseContext: HBaseContext,
@transient val filter: Option[SparkSQLPushDownFilter] = None,
val columns: Seq[Field] = Seq.empty
) extends RDD[Result](relation.sqlContext.sparkContext, Nil){
override def getPartitions: Array[Partition] = {
val regions = RegionResource(relation)
logDebug(s"There are ${regions.size} regions")
val ps = regions.flatMap { x =>
...
}.toArray
...
ps.asInstanceOf[Array[Partition]]
}
...
}常见问题
在python里获取SparkSession时报错 PythonUtils.getEncryptionEnabled does not exist in the JVM:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
...
self._encryption_enabled = self._jvm.PythonUtils.getEncryptionEnabled(self._jsc)
File "/disk1/anaconda3/lib/python3.6/site-packages/py4j/java_gateway.py", line 1487, in __getattr__
"{0}.{1} does not exist in the JVM".format(self._fqn, name))
py4j.protocol.Py4JError: org.apache.spark.api.python.PythonUtils.getEncryptionEnabled does not exist in the JVM原因是pyspark版本与spark版本不匹配,用下面命令可以查看pyspark当前版本,如果过低需要卸载并安装新版。
> pip show pyspark
Name: pyspark
Version: 2.3.0
> pip install pip -U -i https://pypi.tuna.tsinghua.edu.cn/simple
> pip uninstall pyspark
> pip install pyspark==3.1.3 -i https://pypi.tuna.tsinghua.edu.cn/simple完整的pyspark版本历史可以在这里查看:https://pypi.org/project/pyspark/#history
启用 SQL Filter pushdown时报错
当使用.option("hbase.spark.pushdown.columnfilter", true)时报错,其实true是默认值,报错信息如下:
java.lang.NoClassDefFoundError: org/apache/hadoop/hbase/spark/datasources/JavaBytesEncoder$解决方法是,需要将前面提到的scala-library等三个jar包放在每个hbase region server节点的lib目录下。参考链接
参考资料
https://spark.apache.org/docs/latest/hadoop-provided.html
https://hbase.apache.org/book.html#_sparksqldataframes
https://spark.apache.org/docs/latest/api/java/org/apache/spark/rdd/RDD.html
https://github.com/LucaCanali/Miscellaneous/blob/master/Spark_Notes/Spark_HBase_Connector.md