问题描述
尝试用下面的命令在hbase shell里创建启用SNAPPY压缩的表,建表命令一直没有返回,直到过了10分钟左右提示错误信息如下:
hbase:012:0> create 'hb_data_2',{NAME=>'DATA', 'COMPRESSION' => 'SNAPPY'}, {NUMREGIONS => 64, SPLITALGO => 'HexStringSplit' }
2022-12-05 19:54:03,386 INFO [ReadOnlyZKClient-taos-1:2181,taos-2:2181,taos-3:2181@0x0e0d9e3f] zookeeper.ZooKeeper (ZooKeeper.java:close(1422)) - Session: 0x284b286aa820049 closed
2022-12-05 19:54:03,387 INFO [ReadOnlyZKClient-taos-1:2181,taos-2:2181,taos-3:2181@0x0e0d9e3f-EventThread] zookeeper.ClientCnxn (ClientCnxn.java:run(524)) - EventThread shut down for session: 0x284b286aa820049
ERROR: The procedure 844 is still running
For usage try 'help "create"'
Took 608.2809 seconds
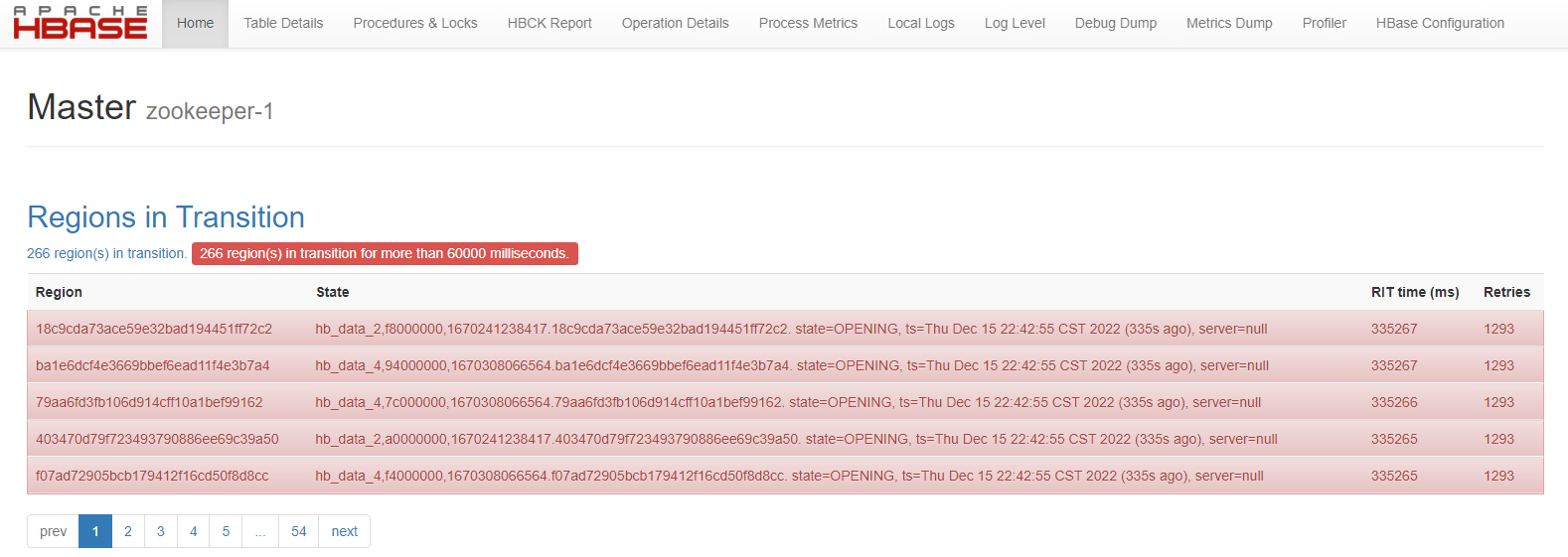
hbase:013:0>在web-ui里看到:
查看日志:
> tail /usr/local/hbase-2.5.1/logs/hbase-root-regionserver-taos-1.log -n200
...
2022-12-05T22:51:11,801 WARN [RS_OPEN_REGION-regionserver/zookeeper-1:16020-0] handler.AssignRegionHandler: Failed to open region hb_data_2,f0000000,1670241238417.d5ced9638670a54fb4172157ee539d34., will report to master
org.apache.hadoop.hbase.DoNotRetryIOException: Compression algorithm 'snappy' previously failed test. Set hbase.table.sanity.checks to false at conf or table descriptor if you want to bypass sanity checks
at org.apache.hadoop.hbase.util.TableDescriptorChecker.warnOrThrowExceptionForFailure(TableDescriptorChecker.java:339) ~[hbase-server-2.5.1.jar:2.5.1]
at org.apache.hadoop.hbase.util.TableDescriptorChecker.checkCompression(TableDescriptorChecker.java:306) ~[hbase-server-2.5.1.jar:2.5.1]
at org.apache.hadoop.hbase.regionserver.HRegion.openHRegion(HRegion.java:7220) ~[hbase-server-2.5.1.jar:2.5.1]
at org.apache.hadoop.hbase.regionserver.HRegion.openHRegionFromTableDir(HRegion.java:7183) ~[hbase-server-2.5.1.jar:2.5.1]
at org.apache.hadoop.hbase.regionserver.HRegion.openHRegion(HRegion.java:7159) ~[hbase-server-2.5.1.jar:2.5.1]
at org.apache.hadoop.hbase.regionserver.HRegion.openHRegion(HRegion.java:7118) ~[hbase-server-2.5.1.jar:2.5.1]
at org.apache.hadoop.hbase.regionserver.HRegion.openHRegion(HRegion.java:7074) ~[hbase-server-2.5.1.jar:2.5.1]
at org.apache.hadoop.hbase.regionserver.handler.AssignRegionHandler.process(AssignRegionHandler.java:147) ~[hbase-server-2.5.1.jar:2.5.1]
at org.apache.hadoop.hbase.executor.EventHandler.run(EventHandler.java:100) ~[hbase-server-2.5.1.jar:2.5.1]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128) ~[?:?]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628) ~[?:?]
at java.lang.Thread.run(Thread.java:829) ~[?:?]
Caused by: org.apache.hadoop.hbase.DoNotRetryIOException: Compression algorithm 'snappy' previously failed test.
at org.apache.hadoop.hbase.util.CompressionTest.testCompression(CompressionTest.java:90) ~[hbase-server-2.5.1.jar:2.5.1]
at org.apache.hadoop.hbase.util.TableDescriptorChecker.checkCompression(TableDescriptorChecker.java:300) ~[hbase-server-2.5.1.jar:2.5.1]
... 10 more
2022-12-05T22:51:11,801 WARN [RS_OPEN_REGION-regionserver/zookeeper-1:16020-2] handler.AssignRegionHandler: Failed to open region hb_data_2,e4000000,1670241238417.722ed7fb3b36599c9ea0176774e3f91c., will report to master
org.apache.hadoop.hbase.DoNotRetryIOException: Compression algorithm 'snappy' previously failed test. Set hbase.table.sanity.checks to false at conf or table descriptor if you want to bypass sanity checks
at org.apache.hadoop.hbase.util.TableDescriptorChecker.warnOrThrowExceptionForFailure(TableDescriptorChecker.java:339) ~[hbase-server-2.5.1.jar:2.5.1]
at org.apache.hadoop.hbase.util.TableDescriptorChecker.checkCompression(TableDescriptorChecker.java:306) ~[hbase-server-2.5.1.jar:2.5.1]
at org.apache.hadoop.hbase.regionserver.HRegion.openHRegion(HRegion.java:7220) ~[hbase-server-2.5.1.jar:2.5.1]
at org.apache.hadoop.hbase.regionserver.HRegion.openHRegionFromTableDir(HRegion.java:7183) ~[hbase-server-2.5.1.jar:2.5.1]
at org.apache.hadoop.hbase.regionserver.HRegion.openHRegion(HRegion.java:7159) ~[hbase-server-2.5.1.jar:2.5.1]
at org.apache.hadoop.hbase.regionserver.HRegion.openHRegion(HRegion.java:7118) ~[hbase-server-2.5.1.jar:2.5.1]
at org.apache.hadoop.hbase.regionserver.HRegion.openHRegion(HRegion.java:7074) ~[hbase-server-2.5.1.jar:2.5.1]
at org.apache.hadoop.hbase.regionserver.handler.AssignRegionHandler.process(AssignRegionHandler.java:147) ~[hbase-server-2.5.1.jar:2.5.1]
at org.apache.hadoop.hbase.executor.EventHandler.run(EventHandler.java:100) ~[hbase-server-2.5.1.jar:2.5.1]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128) ~[?:?]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628) ~[?:?]
at java.lang.Thread.run(Thread.java:829) ~[?:?]
Caused by: org.apache.hadoop.hbase.DoNotRetryIOException: Compression algorithm 'snappy' previously failed test.
at org.apache.hadoop.hbase.util.CompressionTest.testCompression(CompressionTest.java:90) ~[hbase-server-2.5.1.jar:2.5.1]
at org.apache.hadoop.hbase.util.TableDescriptorChecker.checkCompression(TableDescriptorChecker.java:300) ~[hbase-server-2.5.1.jar:2.5.1]
... 10 more
2022-12-05T22:51:11,801 INFO [RS_OPEN_REGION-regionserver/zookeeper-1:16020-1] handler.AssignRegionHandler: Open hb_data_2,,1670241238417.ec86493893d7742525919263abd01c2c.
2022-12-05T22:51:11,802 INFO [RS_OPEN_REGION-regionserver/zookeeper-1:16020-1] regionserver.HRegion: Closing region hb_data_2,,1670241238417.ec86493893d7742525919263abd01c2c.
2022-12-05T22:51:11,802 INFO [RS_OPEN_REGION-regionserver/zookeeper-1:16020-1] regionserver.HRegion: Closed hb_data_2,,1670241238417.ec86493893d7742525919263abd01c2c.
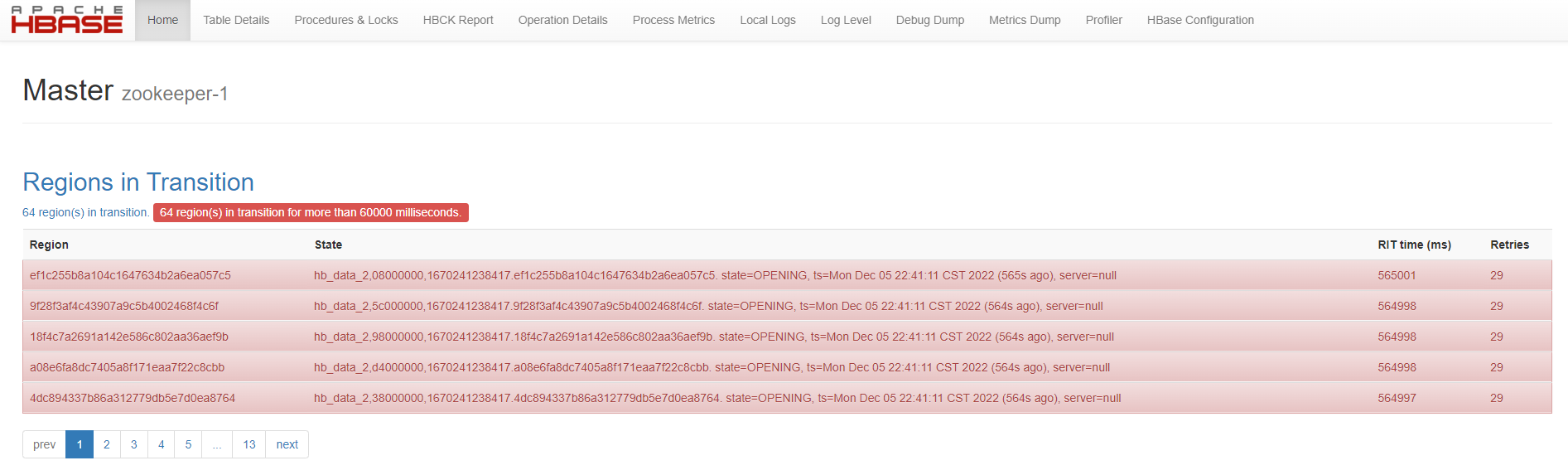
...此时表处于ENABLING状态:
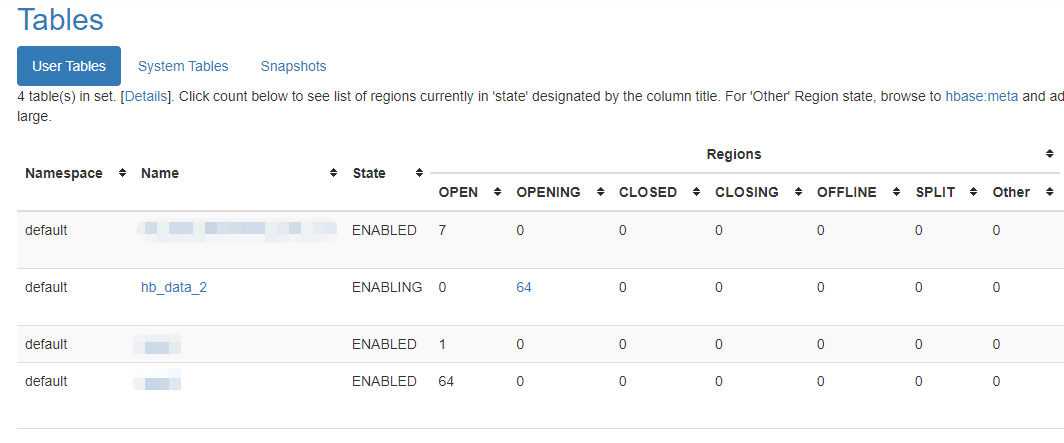
尝试删除,但删除命令也会死住直到超时:
hbase:017:0> drop 'hb_data_2'
ERROR: The procedure 2829 is still running
For usage try 'help "drop"'
Took 668.4171 seconds
hbase:018:0>尝试更换算法为LZ4,仍然提示类似错误:
org.apache.hadoop.hbase.DoNotRetryIOException: Compression algorithm 'lz4' previously failed test. Set hbase.table.sanity.checks to false at conf or table descriptor if you want to bypass sanity checks
at org.apache.hadoop.hbase.util.TableDescriptorChecker.warnOrThrowExceptionForFailure(TableDescriptorChecker.java:339) ~[hbase-server-2.5.1.jar:2.5.1]
at org.apache.hadoop.hbase.util.TableDescriptorChecker.checkCompression(TableDescriptorChecker.java:306) ~[hbase-server-2.5.1.jar:2.5.1]
at org.apache.hadoop.hbase.regionserver.HRegion.openHRegion(HRegion.java:7220) ~[hbase-server-2.5.1.jar:2.5.1]
at org.apache.hadoop.hbase.regionserver.HRegion.openHRegionFromTableDir(HRegion.java:7183) ~[hbase-server-2.5.1.jar:2.5.1]
at org.apache.hadoop.hbase.regionserver.HRegion.openHRegion(HRegion.java:7159) ~[hbase-server-2.5.1.jar:2.5.1]
at org.apache.hadoop.hbase.regionserver.HRegion.openHRegion(HRegion.java:7118) ~[hbase-server-2.5.1.jar:2.5.1]
at org.apache.hadoop.hbase.regionserver.HRegion.openHRegion(HRegion.java:7074) ~[hbase-server-2.5.1.jar:2.5.1]
at org.apache.hadoop.hbase.regionserver.handler.AssignRegionHandler.process(AssignRegionHandler.java:147) ~[hbase-server-2.5.1.jar:2.5.1]
at org.apache.hadoop.hbase.executor.EventHandler.run(EventHandler.java:100) ~[hbase-server-2.5.1.jar:2.5.1]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128) ~[?:?]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628) ~[?:?]
at java.lang.Thread.run(Thread.java:829) ~[?:?]
Caused by: org.apache.hadoop.hbase.DoNotRetryIOException: Compression algorithm 'lz4' previously failed test.
at org.apache.hadoop.hbase.util.CompressionTest.testCompression(CompressionTest.java:90) ~[hbase-server-2.5.1.jar:2.5.1]
at org.apache.hadoop.hbase.util.TableDescriptorChecker.checkCompression(TableDescriptorChecker.java:300) ~[hbase-server-2.5.1.jar:2.5.1]
... 10 more解决方案
在每个节点的hbase-site.xml里添加如下配置:
<property>
</name>hbase.table.sanity.checks</name>
<value>false</value>
</property>然后重启hbase集群:
> stop-hbase.sh
> start-hbase.sh重新尝试建表(要换一个表名):
hbase:008:0> create 'hb_data_5',{NAME=>'DATA', 'COMPRESSION' => 'SNAPPY'}, {NUMREGIONS => 64, SPLITALGO => 'HexStringSplit' }
2022-12-06 15:30:37,106 INFO [main] client.HBaseAdmin (HBaseAdmin.java:postOperationResult(3591)) - Operation: CREATE, Table Name: default:hb_data_5, procId: 13870 completed
Created table hb_data_5
Took 2.2455 seconds
=> Hbase::Table - hb_data_5
hbase:009:0>但是返现原先的表无法禁用并删除(HBase里删表必须先disable):
hbase:005:0> disable 'hb_data_2'
2022-12-06 15:28:16,517 INFO [main] client.HBaseAdmin (HBaseAdmin.java:rpcCall(926)) - Started disable of hb_data_2
ERROR: Table hb_data_2 is disabled!
For usage try 'help "disable"'
Took 0.0529 seconds
hbase:006:0> drop 'hb_data_2'
ERROR: Table org.apache.hadoop.hbase.TableNotDisabledException: Not DISABLED; tableName=hb_data_2, state=ENABLING
at org.apache.hadoop.hbase.master.HMaster.checkTableModifiable(HMaster.java:2786)
at org.apache.hadoop.hbase.master.procedure.DeleteTableProcedure.prepareDelete(DeleteTableProcedure.java:241)
at org.apache.hadoop.hbase.master.procedure.DeleteTableProcedure.executeFromState(DeleteTableProcedure.java:90)
at org.apache.hadoop.hbase.master.procedure.DeleteTableProcedure.executeFromState(DeleteTableProcedure.java:58)
at org.apache.hadoop.hbase.procedure2.StateMachineProcedure.execute(StateMachineProcedure.java:188)
at org.apache.hadoop.hbase.procedure2.Procedure.doExecute(Procedure.java:922)
at org.apache.hadoop.hbase.procedure2.ProcedureExecutor.execProcedure(ProcedureExecutor.java:1648)
at org.apache.hadoop.hbase.procedure2.ProcedureExecutor.executeProcedure(ProcedureExecutor.java:1394)
at org.apache.hadoop.hbase.procedure2.ProcedureExecutor.access$1000(ProcedureExecutor.java:75)
at org.apache.hadoop.hbase.procedure2.ProcedureExecutor$WorkerThread.runProcedure(ProcedureExecutor.java:1960)
at org.apache.hadoop.hbase.trace.TraceUtil.trace(TraceUtil.java:216)
at org.apache.hadoop.hbase.procedure2.ProcedureExecutor$WorkerThread.run(ProcedureExecutor.java:1987)
should be disabled!
For usage try 'help "drop"'
Took 0.0226 seconds