一、环境信息
CentOS 7.9
TDengine 3.1.0.0
OpenJDK 11
二、问题现象
一个数据接入程序,定时将数据从指定文件导入到TDengine,发现每天执行的约1000次导入作业里,有1%~2%是失败的,查询失败作业的日志可以看到抛出如下异常:
[2023-08-07 08:35:00.370] [INFO] [INFO ][2023-08-07 08:33:36] 导入中 2001637/QiJia003/1650038400000/Sec_20220416.csv, 已成功导入 51000 行, 182 MB
[2023-08-07 08:35:06.980] [INFO] [INFO ][2023-08-07 08:33:34] 导入中 2001637/QiJia001/1650038400000/Sec_20220416.csv, 已成功导入 57000 行, 183 MB
[2023-08-07 08:35:00.875] [ERROR] create connection SQLException, url: jdbc:TAOS://:/repo_QiJia_1sec, errorCode -2147483637, state
java.sql.SQLException: TDengine ERROR (8000000b): Unable to establish connection
at com.taosdata.jdbc.TSDBError.createSQLException(TSDBError.java:76) ~[k2box-storage-taos3-2.2.5.jar:?]
at com.taosdata.jdbc.TSDBJNIConnector.executeQuery(TSDBJNIConnector.java:119) ~[k2box-storage-taos3-2.2.5.jar:?]
at com.taosdata.jdbc.TSDBStatement.executeQuery(TSDBStatement.java:47) ~[k2box-storage-taos3-2.2.5.jar:?]
at com.alibaba.druid.pool.DruidAbstractDataSource.validateConnection(DruidAbstractDataSource.java:1419) ~[k2box-storage-taos3-2.2.5.jar:?]
at com.alibaba.druid.pool.DruidAbstractDataSource.createPhysicalConnection(DruidAbstractDataSource.java:1719) ~[k2box-storage-taos3-2.2.5.jar:?]
at com.alibaba.druid.pool.DruidDataSource$CreateConnectionThread.run(DruidDataSource.java:2813) ~[k2box-storage-taos3-2.2.5.jar:?]
[2023-08-07 08:35:00.883] [ERROR] create connection SQLException, url: jdbc:TAOS://:/repo_QiJia_1sec, errorCode -2147483637, state
java.sql.SQLException: TDengine ERROR (8000000b): Unable to establish connection
at com.taosdata.jdbc.TSDBError.createSQLException(TSDBError.java:76) ~[k2box-storage-taos3-2.2.5.jar:?]
at com.taosdata.jdbc.TSDBJNIConnector.executeQuery(TSDBJNIConnector.java:119) ~[k2box-storage-taos3-2.2.5.jar:?]
at com.taosdata.jdbc.TSDBStatement.executeQuery(TSDBStatem三、问题排查
由于此环境的TDengine是不久前从2.6.0升级到3.1.0.0的,升级之前没有这个问题,所以一开始怀疑是TDengine的新版本有问题,或者是新版本的默认参数与旧版本不同导致的。但尝试修改了服务端和客户端(连接池)的各种参数后问题依旧。用ulimit -n和lsof -p查询打开的文件数量和文件上限也在正常范围内。
后来考虑是否作业(docker容器)消耗资源有异常,查看资源占用图表时发现折线图有向反方向走的情况(下图红色箭头指向的位置),说明服务器系统时间有倒流的情况。
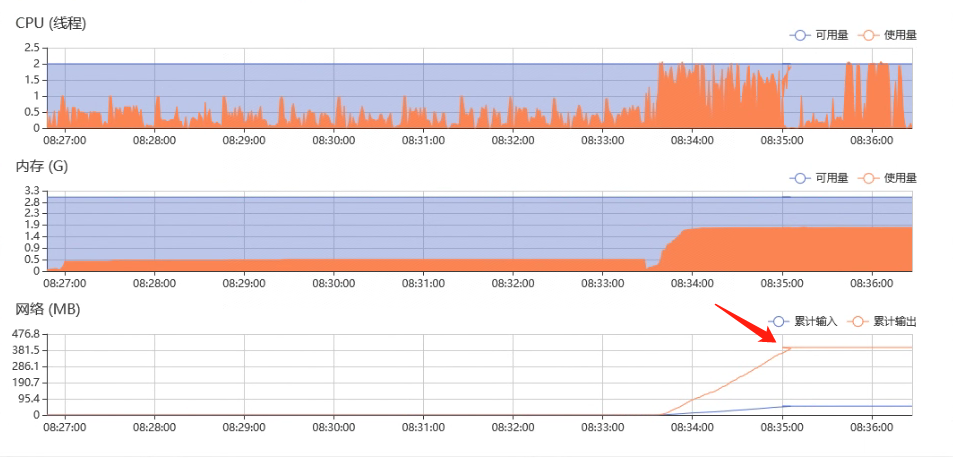
仔细查看前面的失败作业日志,其实也有时间戳倒流的现象,并且连接失败现象与时间戳倒流是同时发生的:
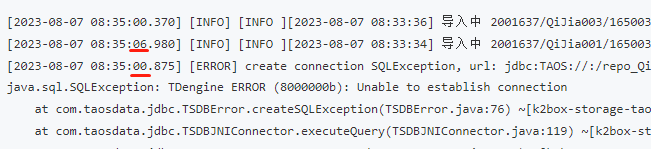
因此将问题嫌疑定位到与系统时钟有关。经过进一步排查发现,此服务器使用ntpdate定期从两台ntp服务器分别进行周期性的对时:
1、每5分钟从服务器10.102.9.31同步时间:
[root@taos-1 ~]# crontab -l
*/5 * * * * /usr/sbin/ntpdate 10.102.9.31 >/dev/null 2>&12、每64秒从服务器10.102.9.32同步时间:
[root@taos-1 ~]# ntpstat
synchronised to NTP server (10.102.9.32) at stratum 3
time correct to within 115 ms
polling server every 64 s
[root@taos-1 ~]#并且服务器10.102.9.32的时钟比10.102.9.31慢7秒左右,这就造成了这台服务器的时钟周期性的向前和向后跳动。当TDengine服务端的时钟改变时,连接池里原有的连接会失效无法连接。
[root@taos-1 ~]# /usr/sbin/ntpdate 10.102.9.32
7 Aug 18:51:23 ntpdate[49651]: step time server 10.102.9.32 offset 7.341666 sec
[root@taos-1 ~]# /usr/sbin/ntpdate 10.102.9.31
7 Aug 18:54:31 ntpdate[1798]: step time server 10.102.9.31 offset -7.200571 sec四、问题解决
从两台服务器分别对时显然是没有必要的,应该是运维人员不了解情况的情况下操作导致的,去掉其中一个对时的任务后即可。这里我们去掉的是ntpstat里配置的对时服务,我们发现它是用chrony服务实现的,因此执行systemctl stop chronyd和systemctl disable chronyd。