GlusterFS是广泛使用的去中心化的分布式文件系统,本文主要介绍GlusterFS里创建不同类型卷的方法,以及如何对已有卷转换类型。
GlusterFS没有提供专门的命令行选项指定卷类型,而是根据根据副本(replica)数量与块(brick)数量关系自动进行判断。
环境信息
CentOS 7.9
GlusterFS 9.4
创建复制卷(Replicate)
GlusterFS的复制卷可以类比于RAID1。当一个volume的replica是brick的整数倍(包含1倍)时创建出来的卷就是复制模式:
> gluster volume create volume1 replica 2 server1:/exp1 server2:/exp2
volume create: volume1: success: please start the volume to access data
> gluster volume start volume1
volume start: volume1: success
> gluster volume info
Volume Name: volume1
Type: Replicate
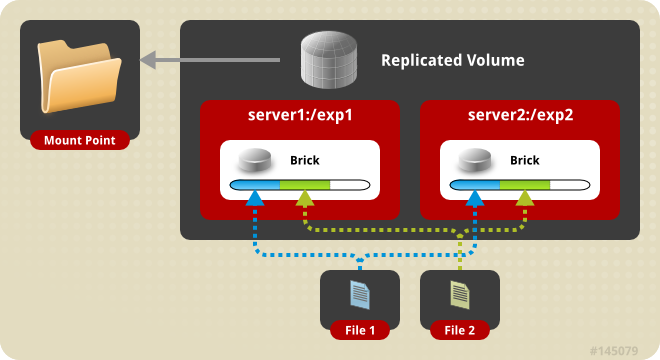
...文件在复制卷上的分布,图片来自GlusterFS官方文档:
创建分布式复制卷(Distributed-Replicate)
GlusterFS的分布式复制卷可以类比于RAID10当brick数量是replica的整数倍(不含1倍)时,创建出来的卷是分布式复制模式:
> gluster volume create volume1 replica 2 server1:/exp1 server2:/exp2 server3:/exp3 server4:/exp4
volume create: volume1: success: please start the volume to access data
> gluster volume start volume1
volume start: volume1: success
> gluster volume info
Volume Name: volume1
Type: Distributed-Replicate
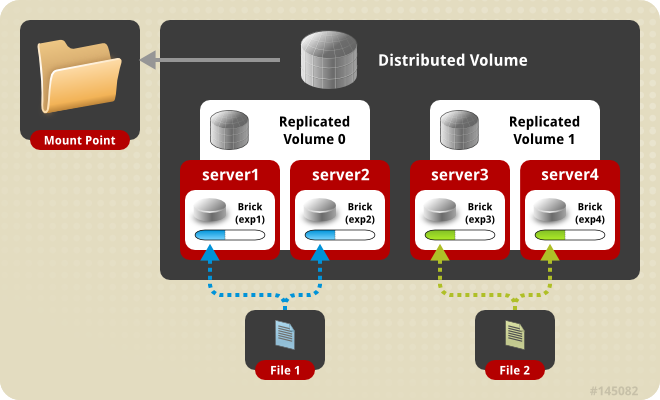
...文件在分布式复制卷上的分布,图片来自GlusterFS官方文档:
将复制卷转为分布式复制卷
假设现在的复制卷是4节点4副本,要将其转换为4节点2副本。转换方法是先收缩位2节点2副本,再扩展为4节点2副本。
注意:收缩副本后,确保不用的旧目录(前面例子中/exp3和/exp4)一定要手工删除,不要直接使用这些目录进行扩容,否则会出现重复文件问题。
> gluster volume info
Volume Name: volume1
Type: Replicate
Volume ID: 38f39495-6678-40c1-9aa7-36399f6285cc
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x 4 = 4
...
# 收缩(对replicate卷需要加force参数)
> gluster volume remove-brick volume1 replica 2 server3:/exp3 server4:/exp4 force
> gluster volume info
Volume Name: volume1
Type: Replicate
Volume ID: 38f39495-6678-40c1-9aa7-36399f6285cc
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x 2 = 2
...
# 扩展(对replicate卷需要加force参数)
> gluster volume add-brick volume1 replica 2 server3:/exp3 server4:/exp4 force
> gluster volume info
Volume Name: volume1
Type: Distributed-Replicate
Volume ID: 38f39495-6678-40c1-9aa7-36399f6285cc
Status: Started
Snapshot Count: 0
Number of Bricks: 1 x 2 = 2
...
# 平衡
> gluster volume rebalance volume1 start
volume rebalance: volume1: success: Rebalance on volume1 has been started successfully. Use rebalance status command to check status of the rebalance process.
ID: 58799899-5f18-4cfb-98d9-96ab91ce6739
> gluster volume rebalance volume1 status
Node ebalanced-files size scanned failures skipped status run time in h:m:s
--------- ----------- ----------- ----------- ----------- ----------- ------------ --------------
server2 2 0Bytes 5 0 0 completed 0:00:00
server3 0 0Bytes 5 0 0 completed 0:00:00
server4 0 0Bytes 5 0 0 completed 0:00:00
localhost 0 0Bytes 5 0 0 completed 0:00:00
当文件数量较多时,平衡所需的时间可能会很长,但这并不影响新文件写入glusterfs。下面是某个生产环境做平衡的过程,大约需要半个月:
Node Rebalanced-files size scanned failures skipped status run time in h:m:s
--------- ----------- ----------- ----------- ----------- ----------- ------------ --------------
10.102.9.127 496771 7.2TB 3340719 0 0 in progress 68:05:36
10.102.9.128 403741 1.2TB 3433837 0 0 in progress 68:05:36
10.102.9.132 1 28Bytes 675030 11 34918 in progress 68:05:31
10.102.9.133 0 0Bytes 673981 0 12583 in progress 68:05:32
10.102.9.134 12 93.2MB 681215 0 15036 in progress 68:05:34
localhost 362702 677.4GB 3143169 0 0 in progress 68:05:36
Estimated time left for rebalance to complete : 322:37:43遇到的问题
1、ls时发现有部分文件和目录名重复:
> ls -l /my/glusterfs
drwxr-xr-x 188 k2data k2data 4096 1月 22 10:14 ALaS
drwxr-xr-x 517 k2data k2data 4096 1月 24 15:19 AoF
drwxr-xr-x 517 k2data k2data 4096 1月 24 15:19 AoF
drwxr-xr-x 358 k2data k2data 4096 1月 22 09:23 BaiGL
drwxr-xr-x 328 k2data k2data 4096 1月 21 20:40 BaiS
drwxr-xr-x 328 k2data k2data 4096 1月 21 20:40 BaiS
...此问题是由于有一个节点的brick目录没有清除,之前认为只要重命名即可(保留文件以便万一需要时恢复),但发现glusterfs似乎会识别到重命名后的文件,观察其下面的.glusterfs隐藏目录里的内容,修改时间一直在变。
后用gluster replace-brick命令从glusterfs里剔除此节点替换为另一个新服务器后问题消失。
2、有些目录权限丢失
例如下面的目录,一些目录权限变成了000,并且owner从k2data变成了root,导致相关程序报错Permission denied。
> ls -l /my/glusterfs
drwxr-xr-x 273 k2data k2data 4096 1月 21 21:44 DiL
d--------- 315 root root 4096 1月 21 21:46 FanC
drwxr-xr-x 338 k2data k2data 4096 1月 27 10:15 FengDS
...出现原因不明,解决方法是手工将这些目录权限改过来(从000改为755):
ls -l | grep d--- | awk '{print $9}' | xargs chown k2data:k2data -R
ls -l | grep d--- | awk '{print $9}' | xargs chmod 755 -R3、文件信息显示为问号
ls -l /my/glusterfs/data/172.17.23.230/20230629
ls: 无法访问/my/gluster/repo_FengDS_hfqfile/data/172.17.23.230/20230629/_zipped.zip: 没有那个文件或目录
总用量 0
-????????? ? ? ? ? ? _zipped.zip经排查是因为这个文件所在的物理目录不正确,例如文件本应在brick1、2、3,但实际被放在了brick4、5、6,如果手工移动到正确位置则问题消失。
产生这个问题的原因是gluster的元信息与文件实际所在物理节点不符,例如gluster认为文件a.txt存放在物理节点1和2上,但由于某种原因a.txt实际存放在节点3和4上。手工将文件移动到正确的位置后问题消失。
4、部分文件脑裂
> gluster volume heal volumn1 info
Brick server1:/my/glusterfs
<gfid:c22fa080-f917-4862-b9d9-a12aff40d392> - Is in split-brain
Status: Connected
Number of entries: 1
Brick server2:/my/glusterfs
<gfid:a60abad3-e42a-49ba-8b8e-463ea656c9cb>
<gfid:12c6e0ae-638c-4d59-96ff-c35a3bda3e07> - Is in split-brain
<gfid:f429f4ad-d935-48a0-bbfa-23407d433e8c> - Is in split-brain
<gfid:6e99bf54-07ab-4c55-92c1-0f5b297079a5> - Is in split-brain
/k2box/apps/com.my.import03/job - Is in split-brain
<gfid:5235e32e-4a7c-457a-ba08-3b7ef61a77e7> - Is in split-brain
<gfid:ba80b4bf-cff3-4dd2-b6a5-cba656431641> - Is in split-brain
/k2box/apps/com.my.import03/job/3471565
<gfid:493df16c-6c91-485a-b6f1-87208395b8f4>
<gfid:afd49274-d9e4-48b2-8814-53fd76fce327> - Is in split-brain
Status: Connected
Number of entries: 10
...自动修复:
> gluster volume heal volumn15、有一个brick的统计信息异常
用gluster volume top命令查询当前各brick打开文件数量,有一个brick的数量明显异常(18446744073709534192个):
> gluster volume top volume1 open | grep fds -B 2
Brick: 10.102.9.126:/my/glusterfs
Current open fds: 0, Max open fds: 1767, Max openfd time: 2023-08-16 04:08:46.556300 +0000
--
186883 /k2box/repos/repo_XuTuan_1sec/.repo/meta.settings
Brick: 10.102.9.134:/my/glusterfs
Current open fds: 18446744073709534192, Max open fds: 18446744073709551615, Max openfd time: 2024-02-01 20:44:34.245111 +0000
--
882 /k2box/apps/com.acme.import01/job/3527701/output/log/stats.log
Brick: 10.102.9.133:/my/glusterfs
Current open fds: 0, Max open fds: 400, Max openfd time: 2024-02-01 13:19:06.438338 +0000
--
2124 /k2box/repos/repo_ZhengXBQ_hive/.repo/batch.settings
Brick: 10.102.9.132:/my/glusterfs
Current open fds: 0, Max open fds: 400, Max openfd time: 2024-02-01 13:19:06.439036 +0000
...重启glusterd服务或重新mount都无效。
参考资料
https://docs.gluster.org/en/latest/Administrator-Guide/Setting-Up-Volumes
请保留原始链接:https://bjzhanghao.cn/p/3276