本文介绍如何使用pytest对python工程进行单元测试和统计测试覆盖率,同时介绍如何测试python程序的运行速度和内存消耗。
一、工程目录结构
测试用例统一放在tests目录下,tests内部目录结构与被测代码的目录结构相同,以便快速定位测试用例代码。
如果环境还没有安装过pytest,先执行pip install pytest进行安装。
二、测试用例内容
测试用例的原则是逻辑尽量简单直白,这样当用例运行失败时能够较快的通过调试定位到问题原因,建议在测试代码里添加必要的注释。另外注意下面几个规则:
- 文件名必须以test_开头,这样pytest命令可以正确识别此文件为测试用例。
- 文件里每个测试方法必须以test_开头,原因同上。
- 如果测试用例引用外部文件,可将文件放在同目录下,然后用os.path.dirname(file)引用py文件所在目录,确保从各个目录执行此测试用例都能正确找到外部文件。
- 如果测试用例生成新的文件,建议用pytest提供的tmp_path参数(文档)作为输出目录,此临时目录下的文件会被自动清理,以免影响测试用例的下次运行。
以下是一个测试用例的例子(test_adapter_csv.py):
from acme.datasets.adapter import *
import os
import pandas as pd
# 验证正常加载csv文件
def test_read_file_to_df():
df = CSVHandler.read_file_to_df(os.path.dirname(__file__), file_type=CSVInputFile.BUFFER)
assert len(df) == 16
# 验证数据正常写出到csv文件
def test_write_df_to_csv(tmp_path):
df = pd.DataFrame()
CSVHandler.write_df_to_csv(df, path=str(tmp_path), file_type=CSVOutputFile.LOT_FLOW)
assert os.path.exists(os.path.join(str(tmp_path), 'RESULT.csv'))为提高代码覆盖率,我们不能只验证输入正常的情况,还应该对处理异常的情况进行验证:
# 验证要加载的csv文件不存在的情况
def test_read_file_to_df_not_exist():
with pytest.raises(FileNotFoundError):
df = CSVHandler.read_file_to_df(os.path.dirname(__file__), file_type=CSVInputFile.DEMAND)三、执行测试用例
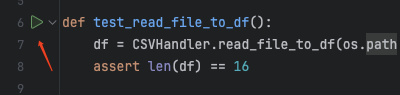
方式1、在IDE里可直接执行test_xxx.py文件里的指定方法
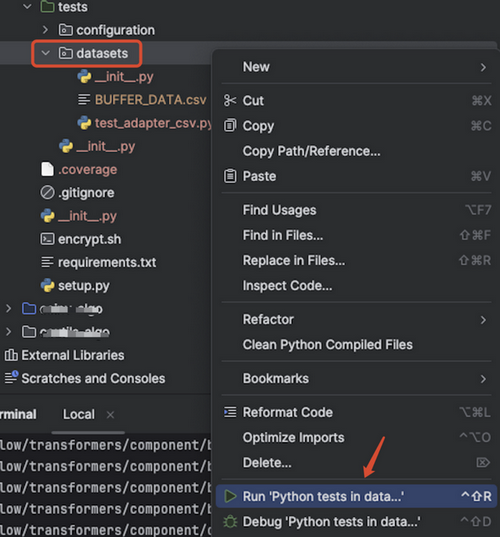
方式2、在IDE里右键点击tests目录选择执行所有测试用例
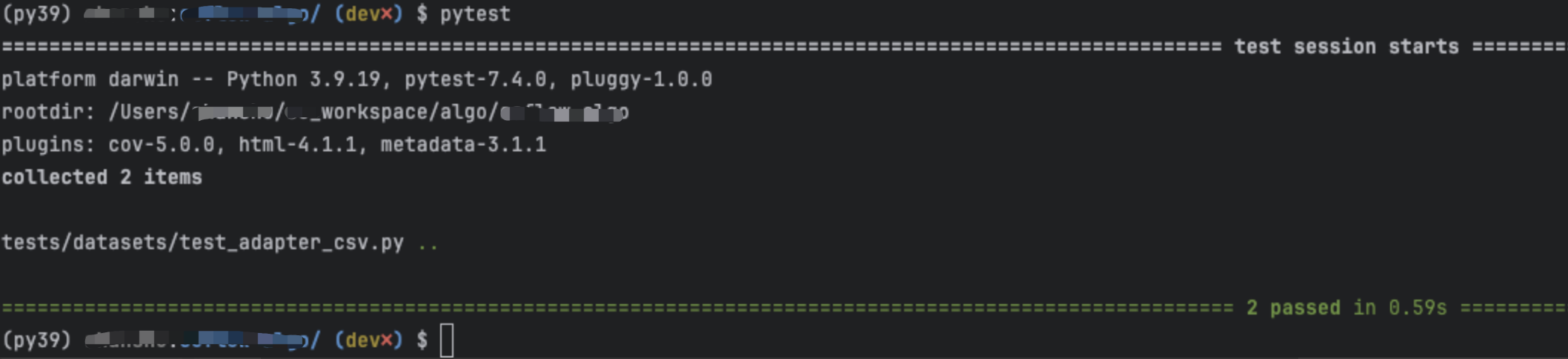
方式3、在命令行里执行pytest命令可以执行所有测试用例
四、统计测试覆盖率
PyCharm专业版里内置了覆盖率工具,在运行时选择"Run with coverage“即可,这里介绍PyCharm社区版如何统计测试覆盖率。
首先确保已安装测试覆盖率组件:
pip install pytest-cov
pip install pytest-html并且确保在tests目录内的每个目录下已包含init.py文件(否则统计时会忽略此目录下的测试用例)。
然后在命令行里执行:
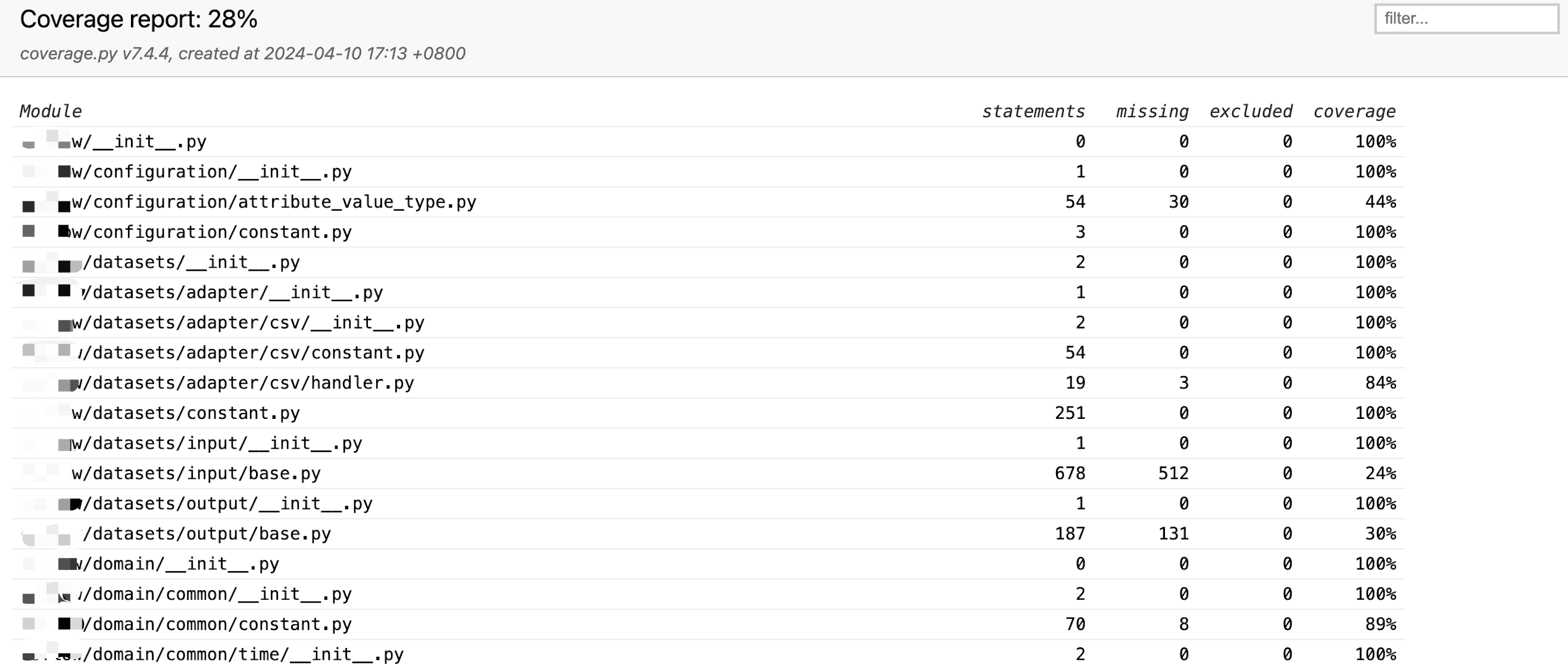
pytest --cov=acme --cov-report=html即可生成测试覆盖率结果文件,放在htmlcov目录下,打开其中的index.html可查看结果。
即使只有一个测试用例,工程的总体覆盖率也已经达到28%,这是因为有很多import、def代码在加载模块时被覆盖到,而实际的业务逻辑代码并没有被覆盖。
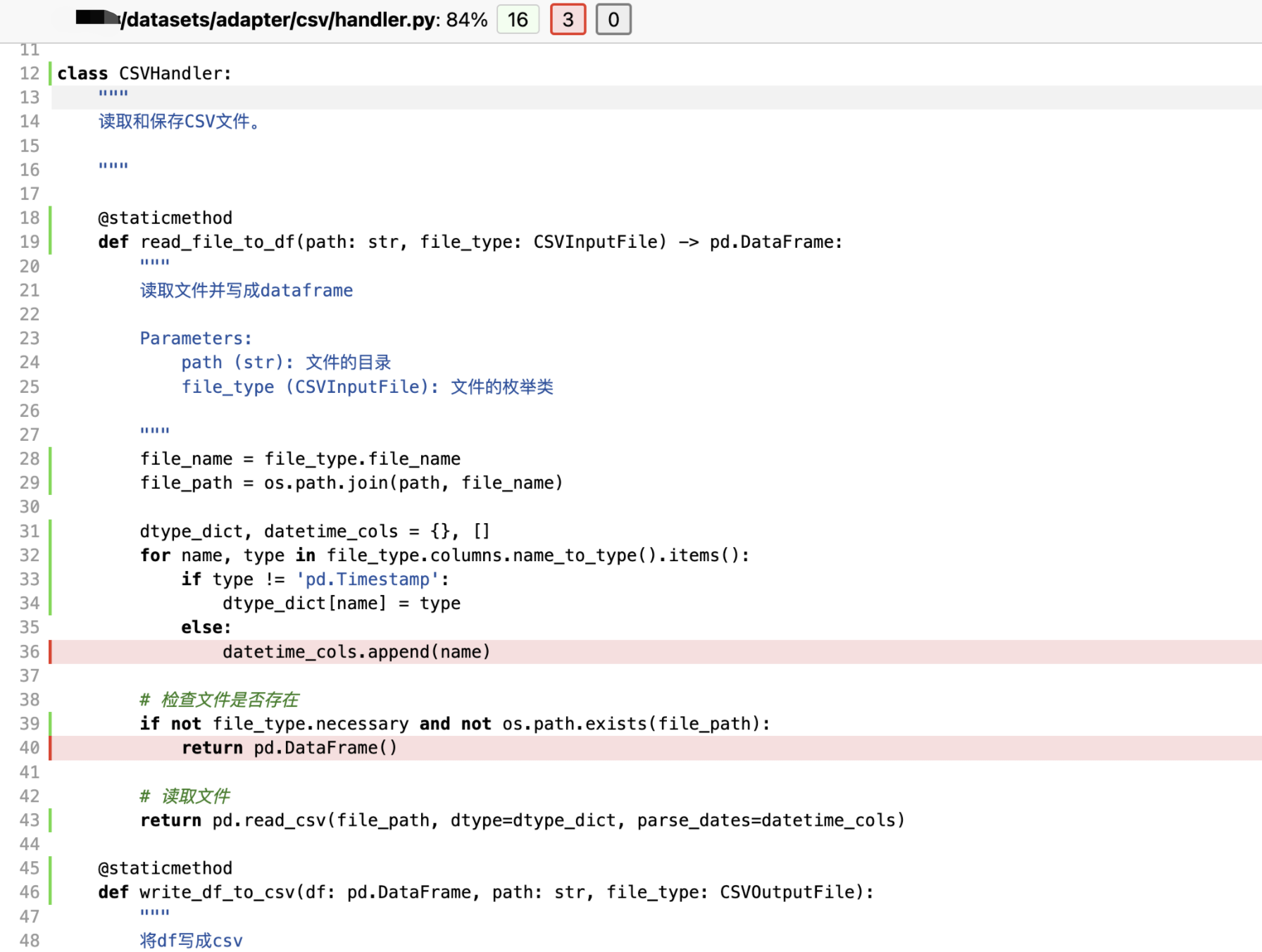
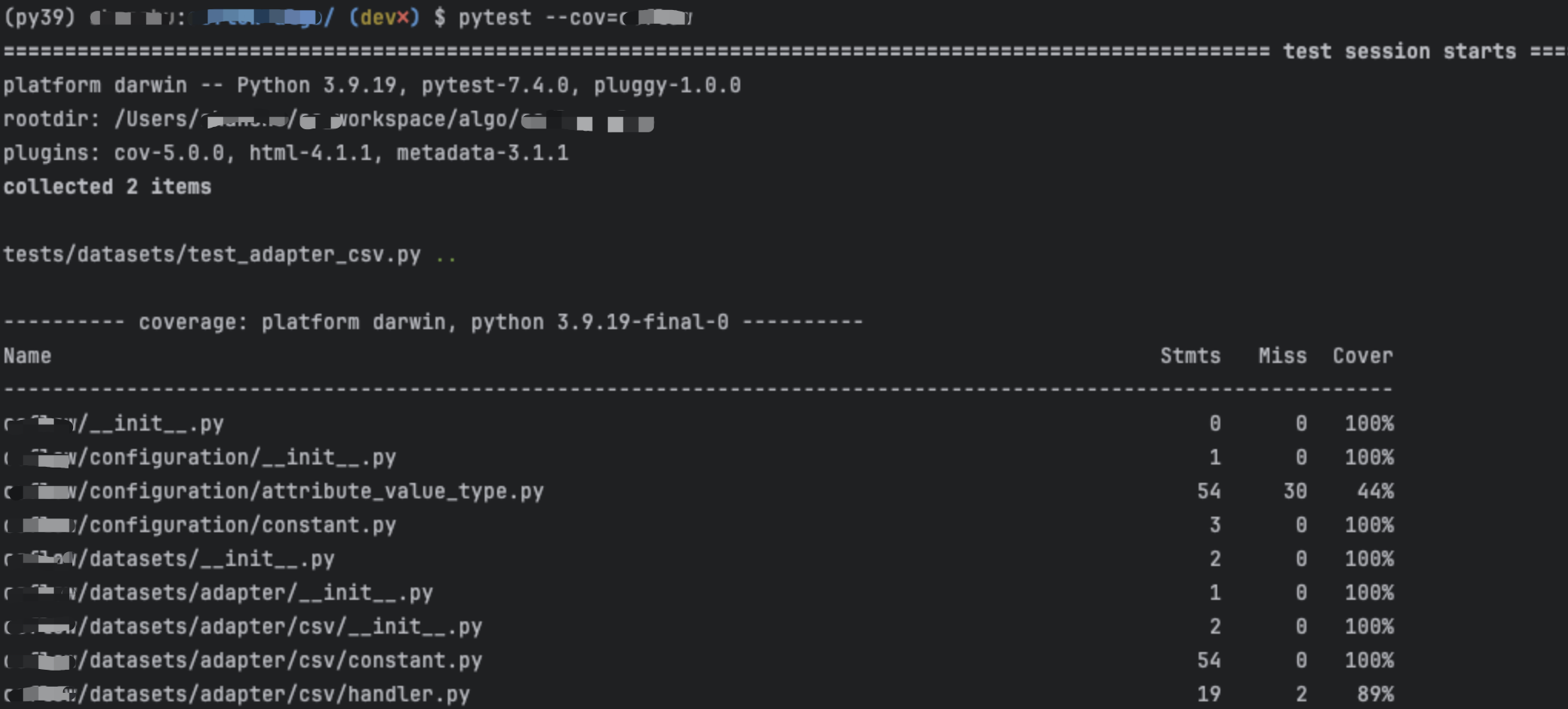
如果忽略 --cov-report=html 参数则会在控制台里输出每个py文件的覆盖率报告,但不会包含逐行的覆盖率结果。
五、性能测试(时间)
方案1:cProfile+Snakeviz
首先安装pytest-profiling组件和snakeviz查看工具:
pip install pytest-profiling
pip install snakeviz在命令行里执行pytest时添加–profile参数即可统计运行时间:
pytest tests/datasets/test_adapter_csv.py --profile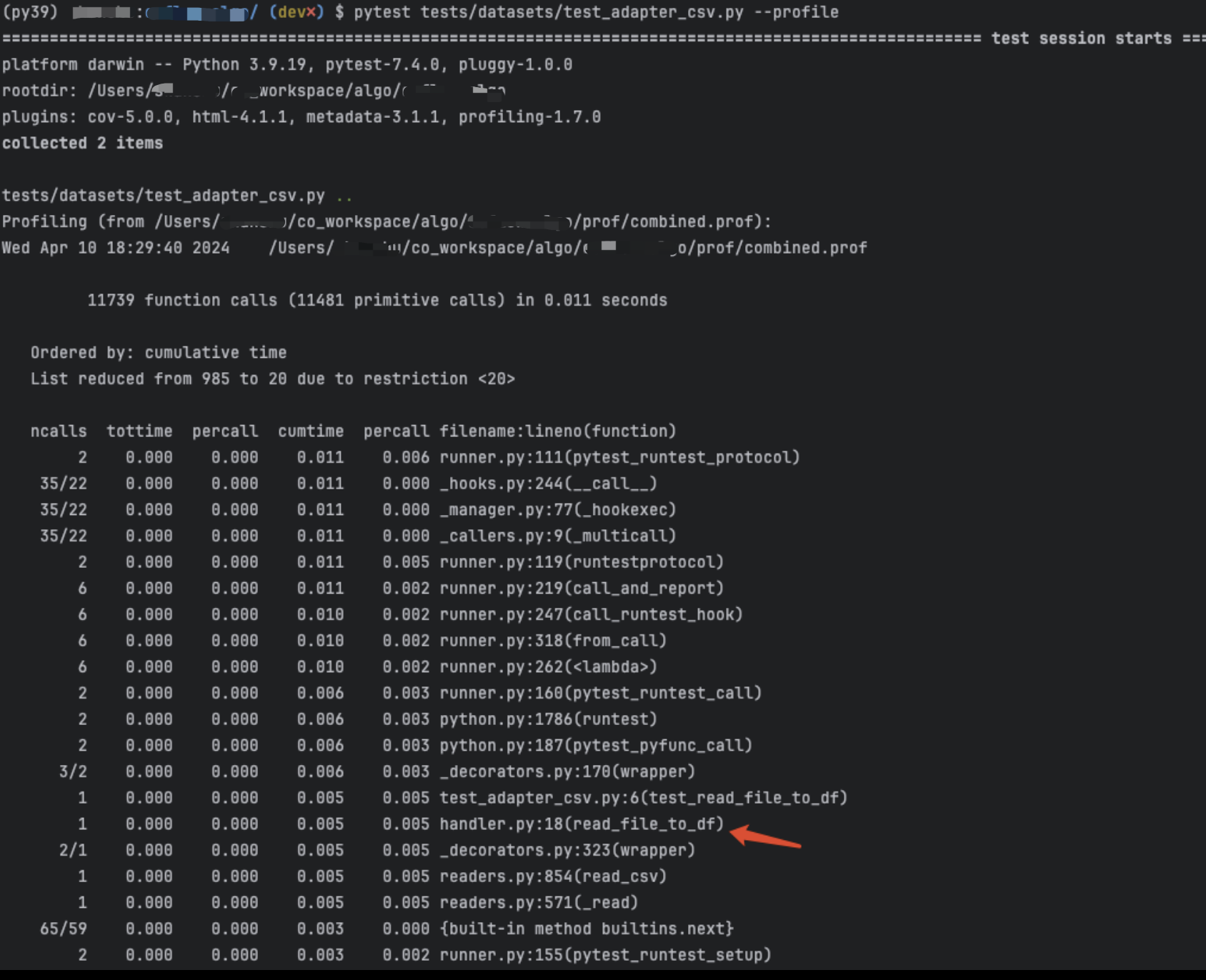
同时会生成二进制格式的统计文件:
使用snakeviz工具查看指定prof文件的内容:
snakeviz prof/combined.prof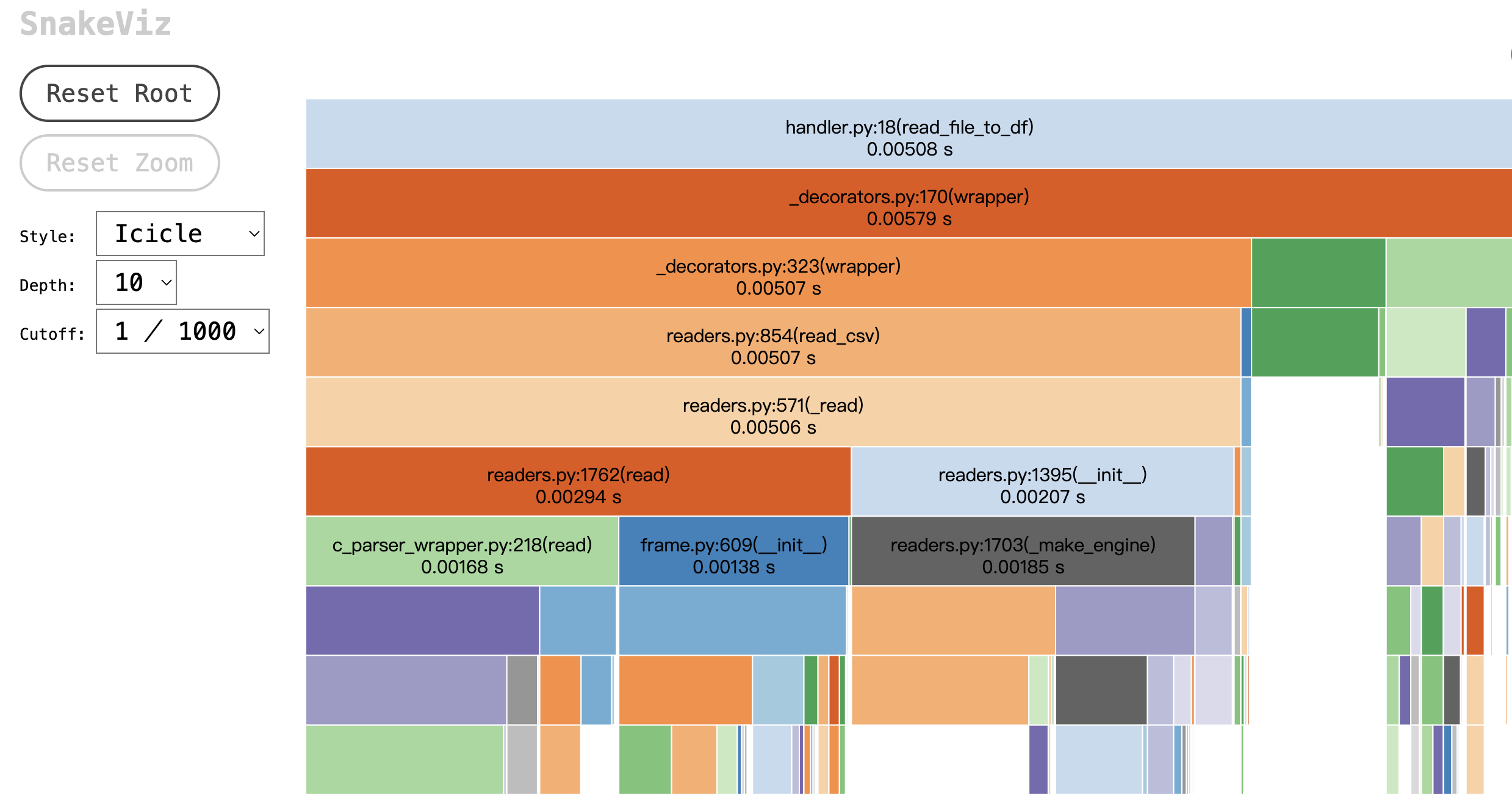
方案2、Viztracer(推荐)
viztracer查看结果的交互方式更加友好,有利于更快速的定位问题,因此推荐使用。
首先安装viztracer组件:
pip install viztracer用viztracer命令运行指定的测试用例:
viztracer --min_duration 0.1ms tests/datasets/test_adapter_csv.py
vizviewer result.json运行结束后会生成result.json文件:
用vizviewer命令查看result.json的内容(会自动启动浏览器):
vizviewer result.json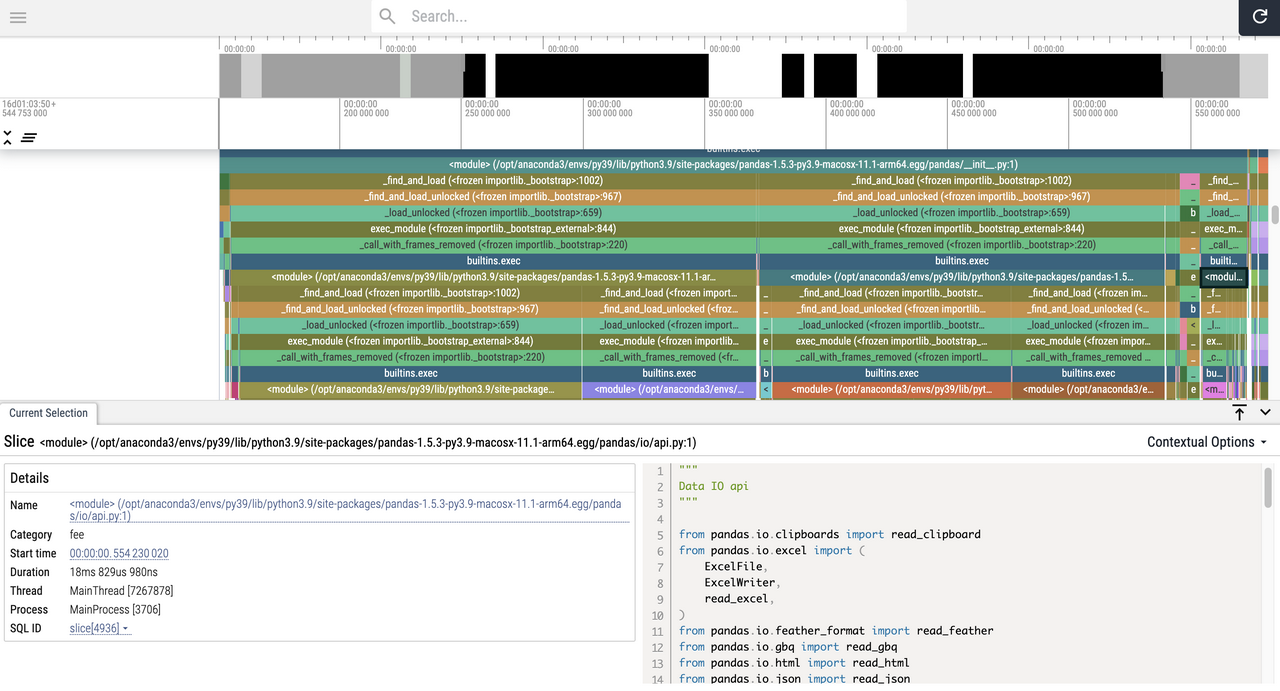
六、性能测试(内存)
a. 整体内存分析
首先安装必要的组件:
pip install memory_profiler
pip install matplotlib使用mprof运行指定的测试用例:
mprof run tests/datasets/test_adapter_csv.py每次运行结束后会生成一个.dat文件:
使用mprof plot命令查看最新一个.dat文件的内容,若不指定文件名则自动查看最新一个文件,图形展示了测试用例执行过程中消耗的内存变化情况:
mprof plot mprofile_20240410185255.dat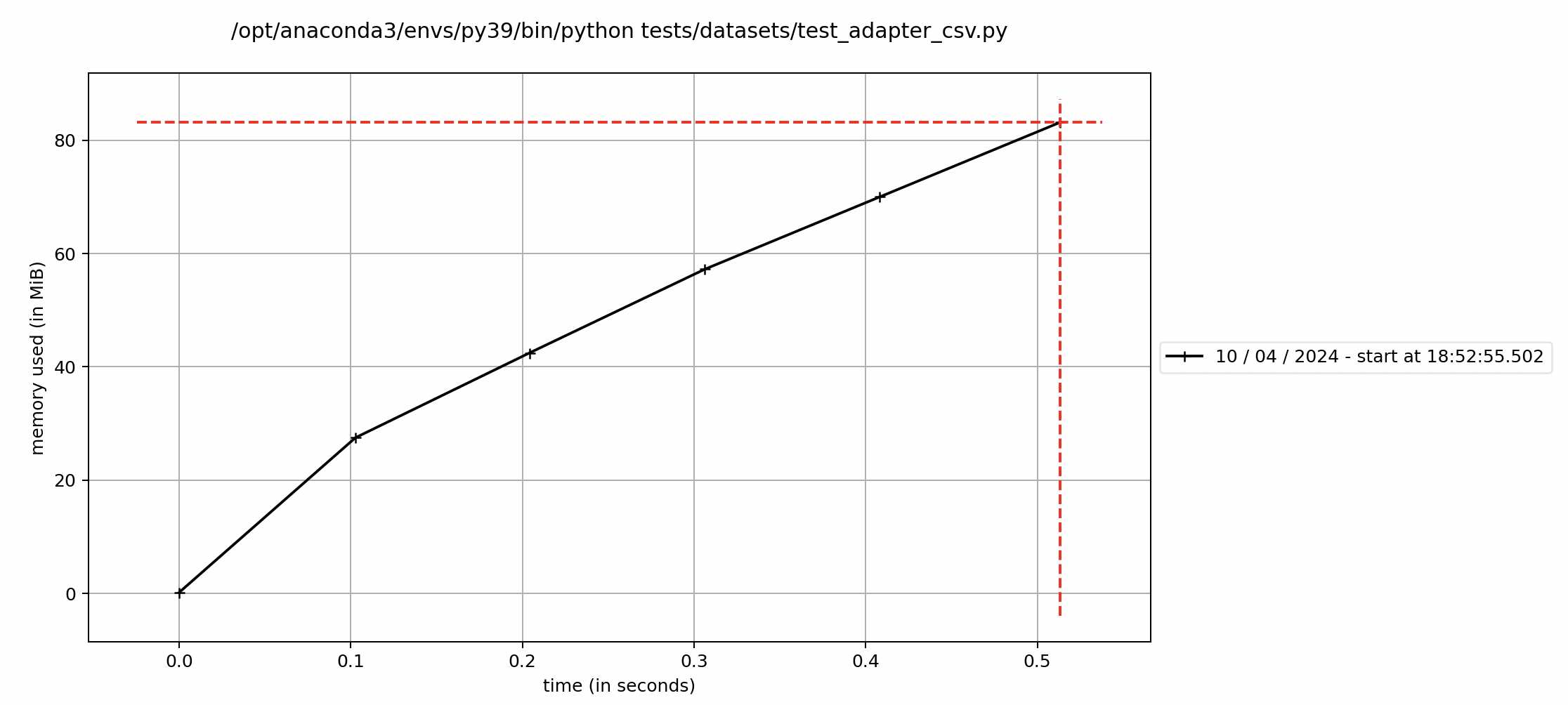
b. 逐行内存分析
有时我们希望分析某个函数或者某几行代码的内存占用,可以用@profile修饰要分析的函数,然后在PyCharm里点击测试函数旁边的运行按钮启动测试用例(命令行里启动不行)。当运行完成后,在控制台里会输出此函数的逐行内存变化。
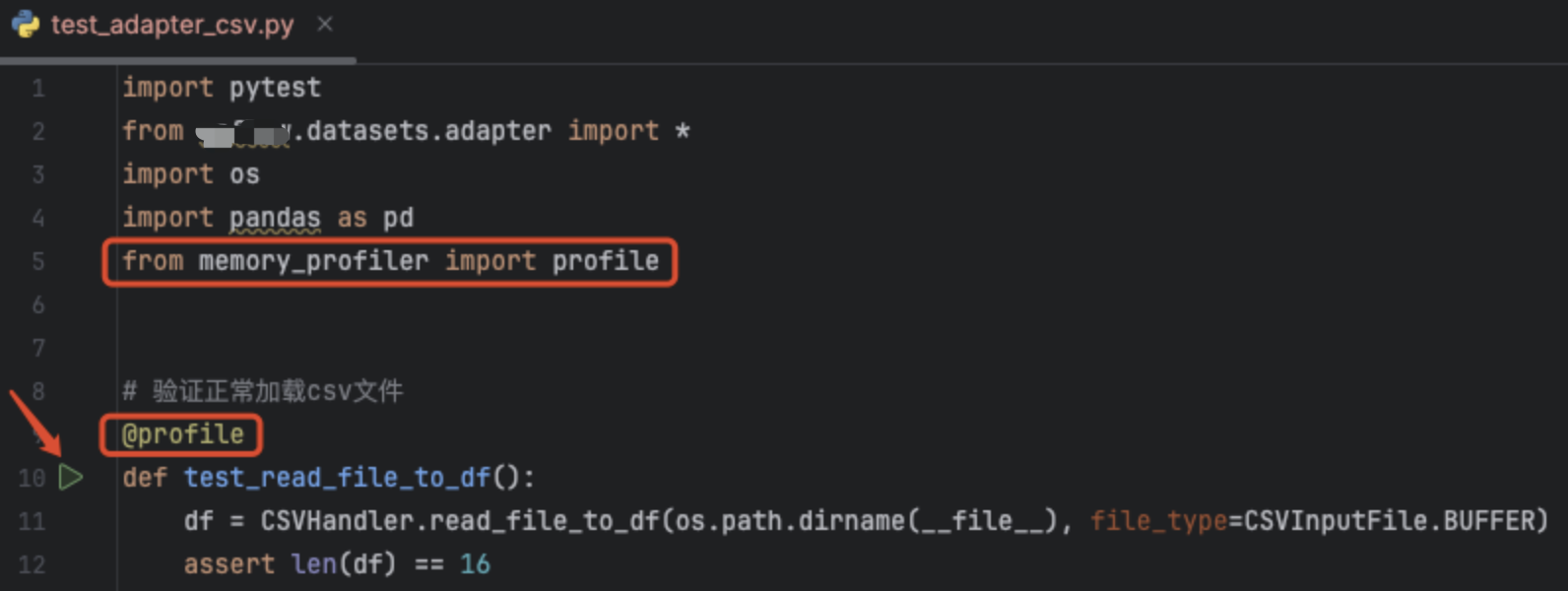
逐行内存占用情况如下图所示,从图中可以看到,读取DataFrame的操作新增占用了0.6MB的内存。

我们也可以用@profile标记多个函数,在PyCharm里批量运行测试用例,这样在测试报告里可以分别查看这些函数的逐行内存占用情况:

请保留原始链接:https://bjzhanghao.cn/p/3330