Beam安装:
https://beam.apache.org/get-started/quickstart-py/
为安装Apache Beam,首先下载安装了最新版python 3.12.4。

> python --version
Python 3.12.4按文档安装beam时报错无法编译wheel:
> pip install apache-beam
...
INFO:root:copying apache_beam\portability\api\org\apache\beam\model\pipeline\v1\schema_pb2.pyi -> build\lib.win-amd64-cpython-312\apache_beam\portability\api\org\apache\beam\model\pipeline\v1
INFO:root:copying apache_beam\portability\api\org\apache\beam\model\pipeline\v1\standard_window_fns_pb2.pyi -> build\lib.win-amd64-cpython-312\apache_beam\portability\api\org\apache\beam\model\pipeline\v1
INFO:root:copying apache_beam\portability\api\standard_coders.yaml -> build\lib.win-amd64-cpython-312\apache_beam\portability\api
INFO:root:running build_ext
INFO:root:building 'apache_beam.coders.coder_impl_row_encoders' extension
error: Microsoft Visual C++ 14.0 or greater is required. Get it with "Microsoft C++ Build Tools": https://visualstudio.microsoft.com/visual-cpp-build-tools/
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
ERROR: Failed building wheel for apache-beam
Building wheel for pyarrow (pyproject.toml) ... error
error: subprocess-exited-with-error
× Building wheel for pyarrow (pyproject.toml) did not run successfully.
│ exit code: 1
╰─> [299 lines of output]
<string>:34: DeprecationWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html
WARNING setuptools_scm.pyproject_reading toml section missing 'pyproject.toml does not contain a tool.setuptools_scm section'
Traceback (most recent call last):
File "C:\Users\zhanghao\AppData\Local\Temp\pip-build-env-0wvk6red\overlay\Lib\site-packages\setuptools_scm\_integration\pyproject_reading.py", line 36, in read_pyproject
section = defn.get("tool", {})[tool_name]
~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^^
KeyError: 'setuptools_scm'
running bdist_wheel
running build
running build_py按报错信息里的提示,从 https://visualstudio.microsoft.com/zh-hans/visual-cpp-build-tools/ 下载了最新版的vc++ buildtools仍然报错。
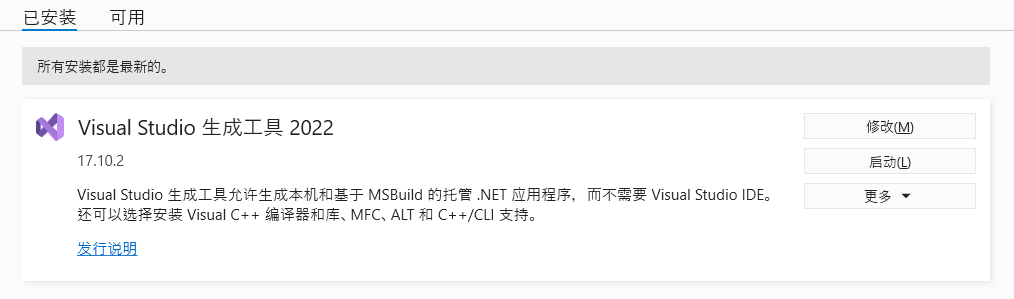
在so上找到类似的问题,其中一个解决方法是安装整个vc++,但需要下载6GB+太重了。发现还有另一个方法,就是不要使用最新版的python,因为最新版python里没有包含一些已编译的包。
This error can happen when using the latest version of Python, e.g. 3.12, because the package wheels were only built for earlier versions of Python
卸载python 3.12.4,安装python 3.9.13,再重新安装beam成功。
> python --version
Python 3.9.13
> pip install apache-beam
...
Using legacy 'setup.py install' for crcmod, since package 'wheel' is not installed.
Using legacy 'setup.py install' for dill, since package 'wheel' is not installed.
Using legacy 'setup.py install' for hdfs, since package 'wheel' is not installed.
Using legacy 'setup.py install' for pyjsparser, since package 'wheel' is not installed.
Using legacy 'setup.py install' for docopt, since package 'wheel' is not installed.
Installing collected packages: pytz, pyjsparser, docopt, crcmod, zstandard, urllib3, tzdata, typing-extensions, six, rpds-py, regex, pyparsing, pyarrow-hotfix, protobuf, packaging, orjson, objsize, numpy, jsonpickle, idna, grpcio, fasteners, fastavro, dnspython, dill, cloudpickle, charset-normalizer, certifi, attrs, async-timeout, tzlocal, requests, referencing, redis, python-dateutil, pymongo, pydot, pyarrow, proto-plus, httplib2, jsonschema-specifications, js2py, hdfs, jsonschema, apache-beam
Running setup.py install for pyjsparser ... done
Running setup.py install for docopt ... done
Running setup.py install for crcmod ... done
Running setup.py install for dill ... done
Running setup.py install for hdfs ... done
Successfully installed apache-beam-2.56.0 async-timeout-4.0.3 attrs-23.2.0 ...