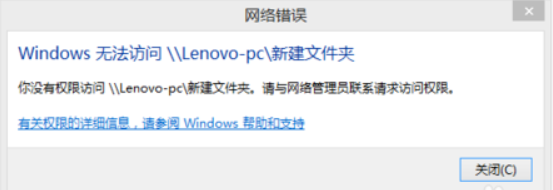
问题:Win7电脑访问Win10电脑的共享文件夹时,提示下面的错误:
解决方法:
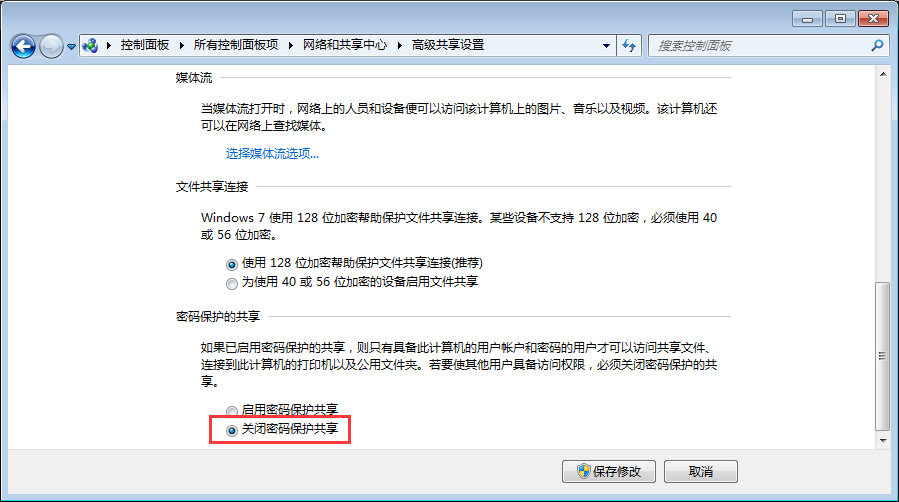
1、在Win10高级共享设置里,勾选“关闭密码保护共享”。这样客户端访问时就不会提示输入用户名密码了(我遇到的情况是即使输入了正确的用户名密码也提示不正确,这个问题并没解决)。
2、在Win10共享的文件夹属性的“安全”页里,加入"Everyone"这个用户并设置足够的权限即可。并不像网上说的那样,需要修改组策略“网络安全:LAN 管理器身份验证级别”。
要查看指定app在手机上占用多少运行内存,首先将手机连接到电脑,然后在命令行执行下面的命令(其中com.my.package.name是app的包名):
adb shell dumpsys meminfo com.my.package.name
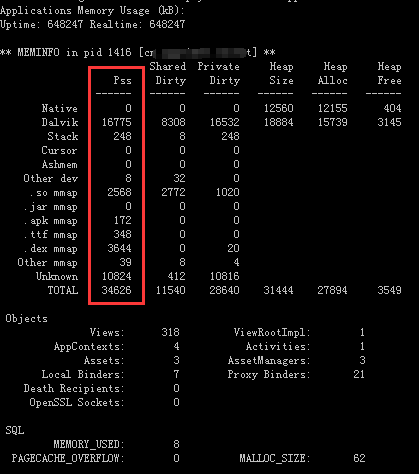
执行结果通常如下,其中Pss那一列的值(单位:kB)是我们主要需要关注的:
参考链接:
adb shell dumpsys meminfo - What is the meaning of each cell of its output?
AndroidStudio 2.3,在小米4c搭载miui8真机上运行程序,提示下面的错误信息:
Installation error: INSTALL_CANCELED_BY_USER
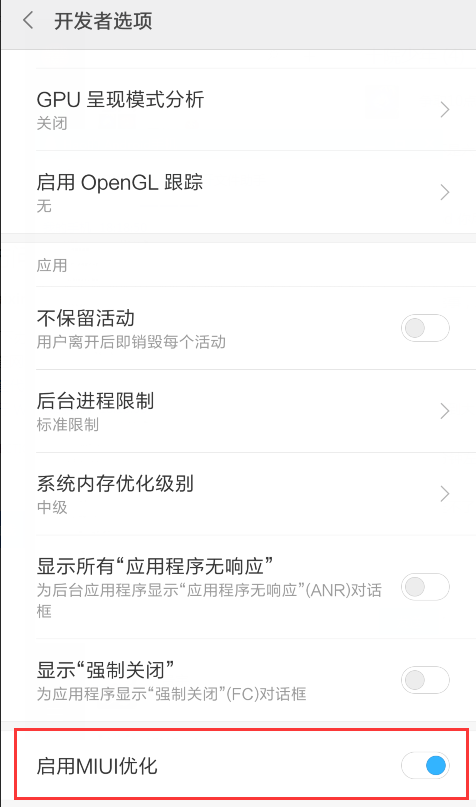
在MIUI开发者选项里,关闭“启用MIUI优化”选项。
关闭此选项时被要求重启,重启后暂时没有发现日常使用有什么变化。
Update: 关闭此选项后发现手机发热和耗电明显,应该是对后台应用的拦截失效导致的。
参考链接:
在apache access log里看到很多一搜(现在好像叫“神马搜索”)的爬虫:
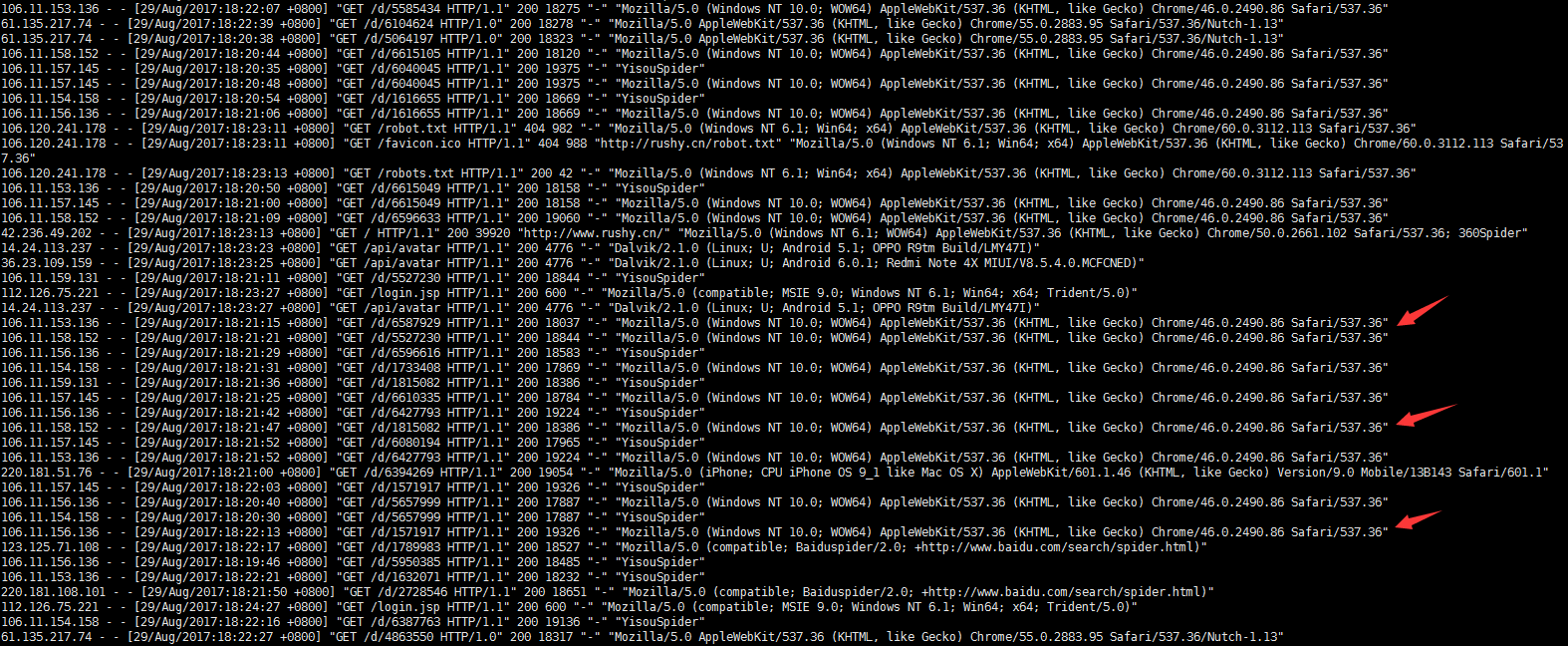
貌似完全不理会robots.txt啊:
User-agent: * Disallow: Crawl-delay: 60
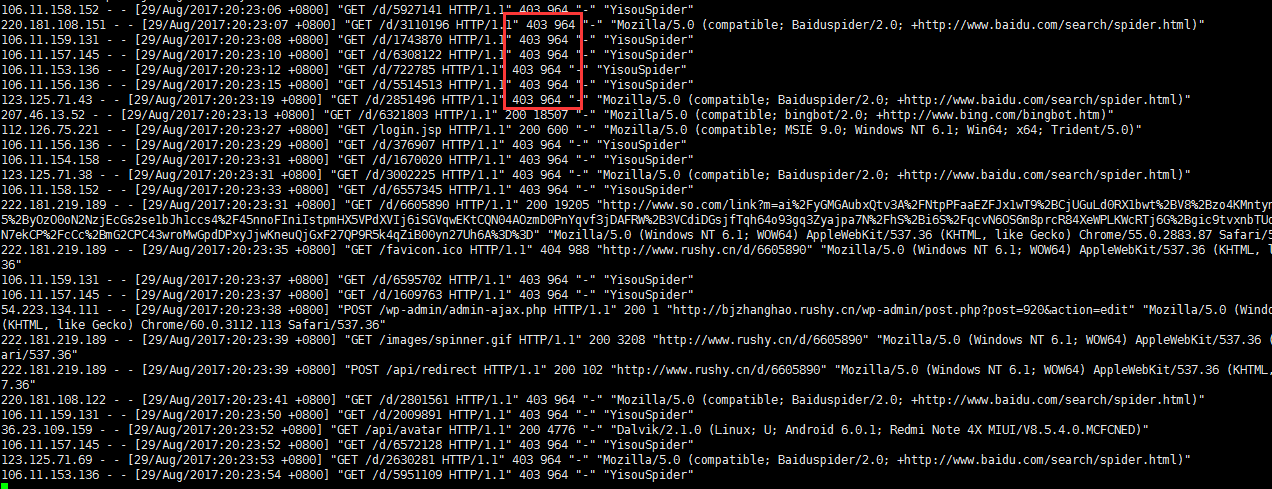
果断在tomcat的server.xml里禁掉IP段:
<Context ...> <!-- 220.181.108.*, 123.125.71.*: baidu spider, 106.11.15*.*: yisou --> <Valve className="org.apache.catalina.valves.RemoteAddrValve" allow="" deny="106.11.15\d.\d+, 220.181.108.\d+, 123.125.71.\d+"/> </Context>
看看效果:
参考资料:
本文介绍Spark的运作原理,并通过在一个实际的Spark运行环境中对数据集进行操作,从而验证这些原理。
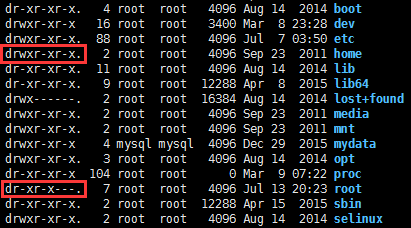
x权限对于目录来说是非常重要的,当用户对某个目录没有x权限时,则不管用户对该目录下的子目录拥有什么样的权限,都将无法对子目录进行任何操作。
通常/root缺省是没有x权限的,因此mysql导出文件(SELECT ... INTO OUTFILE)到/root下的任何目录都会提示无法写入,不论这个目录的owner是谁,也不论这个目录是否777权限:
ERROR 1 (HY000) at line 1: Can't create/write to file '/root/my/out.csv' (Errcode: 13)
而/home缺省是有x权限的,因此在这个目录下mysql用户的文件夹,是可以用于mysql导出到文件的。

进入zookeeper命令行,zookeeper默认端口号是2181:
$ bin/zkCli.sh -server 127.0.0.1:2181
Zookeeper命令行下的操作和文件系统比较接近。例如可以对指定目录进行列表(注意目录名必须以/开头):
ls /
创建一个znode,同时为这个znode设置一个数据(my_data),一个znode只能有一个数据:
create /zk_test my_data
更改znode上的数据(会覆盖之前设置的数据):
set /zk_test my_data_2
读取znode上的数据:
get /zk_test
删除znode:
delete /zk_test
参考资料:
一个mapreduce执行完成后,控制台会输出一些执行过程中产生的数据,通过分析这些数据可以帮助我们验证执行过程是否正常。
Kafka是一个高性能的分布式消息队列系统,它的诀窍在于充分利用了“顺序读写磁盘性能大于随机读写内存”的事实。The Pathologies of Big Data