在Web应用程序里,分页总让我们开发人员感到很头疼,倒不是因为技术上有多么困难,只是本来和业务没有太多关系的这么一个问题,你却得花不少功夫来处理。要是稍不留神,时不时出点问题就更郁闷了。我现在做的一个项目也到了该处理分页的时候了,感觉以前处理得都不好,所以这次有所改变,基本目标是在现有(未分页)的代码基础上,尽量少做修改,并且同样的代码可以应用于不同模块的分页。以下就是我用的方法:
首先,考虑分页绝大多数发生在列表时,组合查询时也需要用到。在我的项目里,列表的Action一般名字为ListXXXActioin,例如客户列表是ListClientsAction等等。在未分页前,ListXXXAction里会把所有的对象取出,通过request.setAttribute()放在request里,然后将请求转向到列表的jsp(例如listClients.jsp)显示出来(你可能会说不要在Action里放业务逻辑,但现在这不是我们考虑的重点)。而分页后,我们只取用户请求页对应的那些对象。为了最大限度的达到代码重用,我做了以下工作:
1、新建一个Pager类,该类有beginPage、endPage、currentPage、pageSize和total等int类型的属性,分别代表开始页、结束页、当前页、每页记录数和总记录数,它主要是让jsp页面显示页导航使用的。请注意currentPage属性是从0开始的。
2、新建一个AbstractListActioin类,并让所有ListXXXAction都继承它。在这个类里覆盖execute()方法,可以在这里判断权限等等,并在判断权限通过后执行一个abstract的act()方法,这个act()由ListXXXAction来实现。
3、在AbstractListAction里增加getPage()方法,用来从request得到用户请求的页码(若未请求则认为是第0页):
protected int getPage(HttpServletRequest request) {
String p = request.getParameter("p");
if (p == null)
return 0;
else
try {
return Integer.parseInt(p);
} catch (NumberFormatException e) {
return 0;
}
}
4、在AbstractListAction里增加makePager()方法,用来向request里增加一个Pager类的实例,供jsp页面显示页导航:
protected Pager makePager(HttpServletRequest request, int total) {
Pager pager=new Pager();
pager.setTotal(total);
pager.setPageSize(Config.getInstance().getPageSize());
pager.setBeginPage(0);
pager.setEndPage(((pager.getTotal()) - 1) / pager.getPageSize() + 1);
pager.setCurrentPage(getPage(request));
return pager;
}
注意在我的项目里,每页记录数是写在配置文件里的,如果你没有配置文件,上面第4行setPageSize()的参数直接填数字即可,例如pager.setPageSize(10);
5、这样,所有的ListXXXAction都可以使用getPage()得到请求的页码,并且能够方便的通过makePager()构造需要放在request里的pager对象了。现在要在从数据库取数据的代码上再做一些修改,即只取所需要的那一部分数据。由于我的项目中使用了Hibernate,所以这个修改也不是很困难。未分页前,在我的ListClientsAction里是通过构造一个Query来得到全部Client的,现在,只要在构造这个Query后再加两句(setMaxResults和setFirstResult)即可:
Query query = ;//构造query的语句
int total = ;//得到总记录数
Pager pager = makePager(request, total);//调用父类中的方法构造一个Pager实例
query.setMaxResults(pager.getPageSize());//设置每页记录数
query.setFirstResult(pager.getCurrentPage() * pager.getPageSize()); //设置开始位置
request.setAttribute(Pager.class.getName(), pager);//把pager放在request里
request.setAttribute(Client.class.getName(), query.list());
目前存在一个问题,就是在上面代码的第二句中,应该是获得总记录数,但我暂时没有特别好的办法不得到全部对象而直接得到记录数,只能很恐怖的用“int total = query.list().size();”,汗……
6、最后,我写了一个页导航的jsp页面pager.jsp,供各个显示列表的jsp来include,代码如下:
<%Pager pager=(Pager)request.getAttribute(Pager.class.getName());%>
<table width="90%" border="0" align="center" cellpadding="2" cellspacing="1" bgcolor="#CCCCCC">
<tr>
<td bgcolor="#EEEEEE" align="right">
<bean:message key="prompt.pager" arg0="<%=String.valueOf(pager.getTotal())%>"/>
[
<%
for(int i=pager.getBeginPage();i<=pager.getEndPage();i++){
if(i==pager.getCurrentPage()){
%>
<%=(i+1)%>
<%}else{
String qs=request.getQueryString()==null?"":request.getQueryString();
String op = "p="+pager.getCurrentPage();//Original page parameter expression
String np = "p="+i;//New expression
if(qs.indexOf(op)==-1)
qs=np+"&"+qs;
qs=qs.replaceAll(op,np);
%>
<a href="<%="?"+qs%>"><%=(i+1)%></a>
<%}%>
<%if(i<pager.getEndPage()-1){%>
<%}%>
<%}%>
]
</td></tr>
</table>
我觉得有必要解释一下,在上面的代码中,关于每一页对应的url是这样处理。request.getQueryString()中可能包含“q=2”这样的页码请求,也可能不包含即缺省请求第0页,所以统一用replaceAll()方法将其去掉,然后将对应的页码请求串(如“q=3”)加在qs的前面。这样做的好处是,每个模块都可以使用这个页导航,并且不会丢失url中的其他参数(例如今后加入排序功能后,url中可能包含“direction=desc”这样的参数)。
05-4-14 Update:我发现在Tomcat4.1和Websphere5.0里,request.getRequestURL()方法得到的地址是不一样的,所以考虑到兼容性,每个页码的链接都使用相对本页的链接。
在列表jsp(listClients.jsp)中,很简单的这样include它(之所以要放在里,是希望在没有记录可显示的时候就不显示页导航了):
<logic:notEmpty name="<%=Client.class.getName()%>">
<%@include file="/pager.jsp"%>
</logic:notEmpty>
经过上面几步的处理,我的客户列表已经可以实现分页了,效果见下图。如果在另外一个模块中也需要分页,比如部门列表时,只需要1、修改ListDeptsAction继承AbstractListAction,2、在ListDeptsAction里增加setMaxResults()和setFirstResults()方法,3、在listDepts.jsp中适当的位置include页导航,就可以了,改动是相当小的。
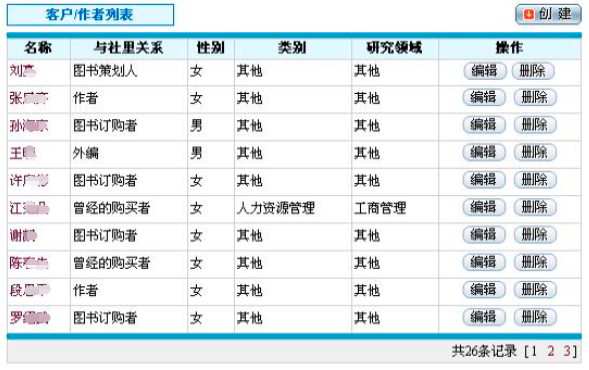
最后,如果希望组合查询的结果也能够分页,必须指定组合查询表单的method属性为“GET”,这样查询要求会被记录在url中,分页导航从而能够正常的工作(每次换页都将查询要求和请求的页码提交)。
搬家前链接:https://www.cnblogs.com/bjzhanghao/archive/2004/12/06/73417.html