OWL-S可以用来描述Web服务,这个帖子将介绍一个非常简单的例子,也许对理解Web服务的组装有些作用。这个服务是对已有Web服务进行组装和执行,所以你并不需要发布自己的Web服务。你需要安装Protege和OWL-S Editor插件,我用的版本前者是3.1 beta build 191,后者是build 15,它们在一起运行得还不错。
所用的Web服务在http://www.bs-byg.dk/hashclass.wsdl,它包含两个方法:HashString和CheckHash,前者用指定编码方式(MD5、SHA1等等)对指定字符串编码,后者根据指定编码方式检查一个字符串(HashString)是否是另一个字符串(OriginString)的编码结果。我们将把这两个方法组装成一个服务,对输入的编码方式和待编码字符串先进行编码,然后检查编码的结果是否正确,如果正确返回true,否则返回false。下面是组装步骤,完整的工程在这里下载。
1、确认你的OWL-S Editor已经安装到Protege里,启动Protege,新建一个owl文件类型的工程,在菜单project->config里勾选上owls选项,按确定后Protege的主界面会多出一个OWL-S Editor页。
2、转到OWL-S Editor页,按左上角的WSDL按钮,在弹出的对话框里输入Web服务的地址http://www.bs-byg.dk/hashclass.wsdl,然后按回车,过一会儿在对话框里会显示出这个Web服务的信息,左边是Operations列表。
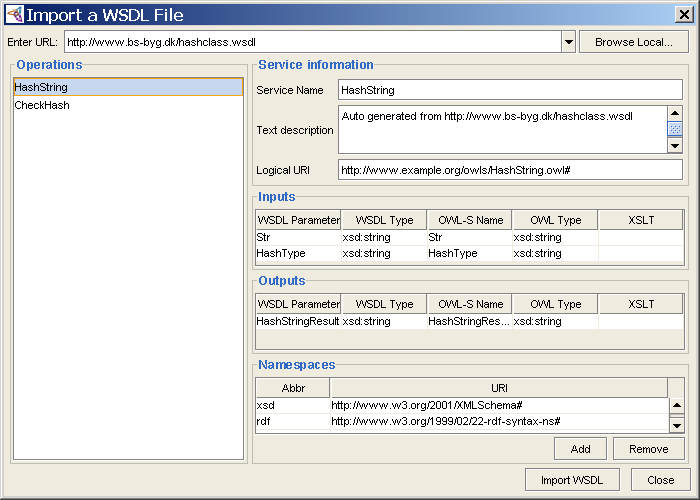
图1 用来导入WSDL的对话框
3、因为每次只能import一个Operation,所以先选择HashString,然后按右下方的Import按钮,这时系统会提示要把生成的owls文件(扩展名为.owl)保存在一个位置,你可以选择任何位置。
4、使用同样的方法把CheckHash方法也导入进来,这样我们就有了两个可用于组装的Web服务了。如果你愿意的话,可以单独执行看看,方法是选择一个Service,然后按绿色的执行按钮。
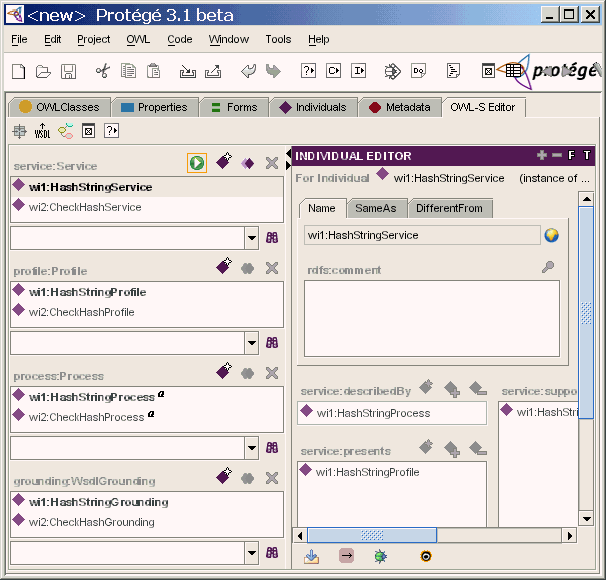
图2 导入的两个服务
5、现在开始组装它们。为此我们新建一个Service实例(按Create Service按钮)、一个Profile实例、一个CompositeProcess实例和一个WSDLGrounding实例,分别命名为myservice、myprofile、myprocess和mygrounding好了。
6、接下来把它们连接起来,首先选中myservice,把它的describedBy属性置为myprocess,presents属性置为myprofile,supports属性置为mygrounding。
7、现在对myprocess进行编辑,OWL-S Editor提供了一个可视化的编辑界面(Visual Editor),利用它可以很方便的定义CompositeProcess的各个步骤。选中myprocess,右边切换到Visual Editor,这里有一些粉红色的按钮用来定制流程。我们首先创建一个Sequence(表示按顺序执行),然后选中这个Sequence,创建两个Perform和一个Produce,每个Perform代表调用一个Web服务,而Produce的作用是在最后得到返回值。这时右边的图形应该像下面这样,因为我们尚未对Perform和Produce进行定制。
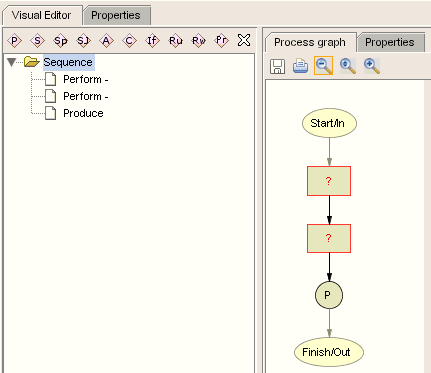
图3 包含三个有用节点的process图
8、在图形的Perform/Produce节点上点一下就可以修改它的属性,先来修改第一个。点一下第一个矩形节点(第一个Perform),在对话框里把process属性设置为wi1:HashStringProcess(注意:如果导入WSDL时改变了前缀,这里就不是wi1),为了方便阅读,把Name属性改为hashPerform。类似的,第二个矩形节点的process属性应该是wi2:CheckHashProcess,Name则改为checkPerform;对于唯一的Produce节点,改名为produce。现在右边的图如下所示。
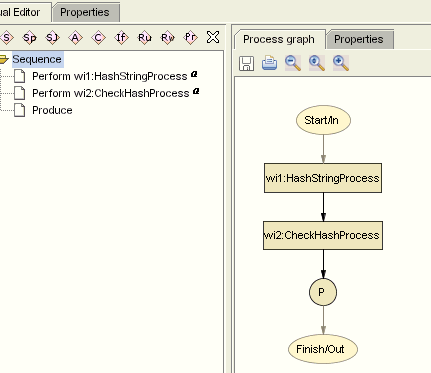
图4 改名后的process图
9、现在从Visual Editor切换到Properties页,在这里为myprocess定义输入和输出参数。它的输入应该是wi1:HashType和wi1:Str,而输出应该是wi2:CheckHashResult,也就是说,对于我们组装出来的Web服务来说,输入是编码类型和待编码字符串,而输出是验证结果。
10、上面我们定义了myprocess拥有的参数,现在就要用到它们了。切换回Visual Editor,在树型列表里选则第一个Perform(hashPerform),把右边切换到Properties页,现在ToParameter属性里还是空白,我们要把myprocess的输入映射到这个Perform,所以按添加按钮把两个输入参数(wi1:HashType和wi1: Str)加到ToParameter里。选中它们中的一个,可以看到右边有BindingType选项,缺省为valueSource这一项,就用它即可,在下面的FromPerform下拉框里只有一个选项TheParentPerform,选中它。在最下面的FromParameter里选择和你选择的ToParameter项一样的那个选项(wi1:HashType->wi1:HashType,wi1:Str->wi1:Str)。
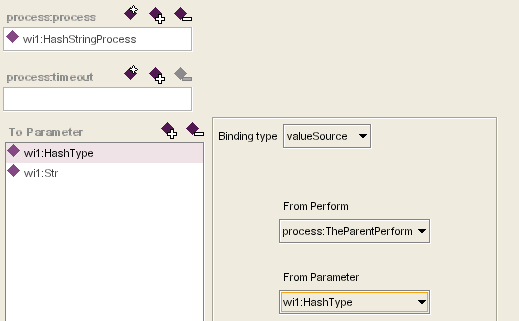
图5 通过参数传递产生“数据流”
11、对于checkPerform,它有三个输入参数,我们希望HashType和hashPerform具有同样的值,所以它的设置和上一步里对HashType的设置一样;OriginalString的设置和上一步的Str一样;HashString属性是上一步得到的结果,所以FromPerform属性应该是hashPerform,FromParameter属性则是wi1:HashStringResult。
12、对produce的设置很简单,在ToParameter属性里加入我们要的结果wi2:CheckHashResult,FromPerform选checkPerform,FromParameter选wi2:CheckHashResult。现在,myprocess对应的process图如下所示。
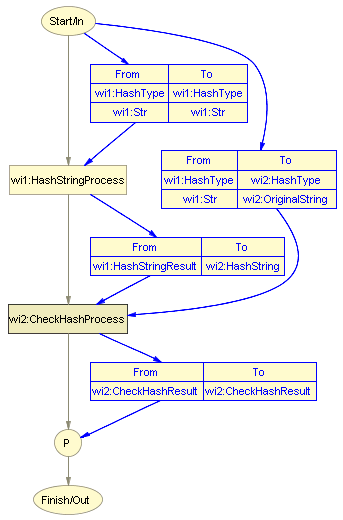
图6 可以从图中看到服务的结构
13、对myprocess的设置到此就结束了,最困难的部分完成了,剩下的工作都很简单和显而易见。选中mygrounding,在它的hasAtomicProcessGrounding属性里加上wi1:HashStringAtomicProcessGrounding和wi2:CheckHashAtomicProcessGrounding。
14、现在myservice已经可以执行了(myprofile里还可以增加一些信息用来描述这个服务)。现在选中myservice,按下执行按钮,在弹出的对话框里HashType框填MD5,Str框填test(任意字符串都可以),然后按Execute按钮就会看到结果,当然,这个服务不论你输入什么字符串都会得到true值,原因不用我说了吧。
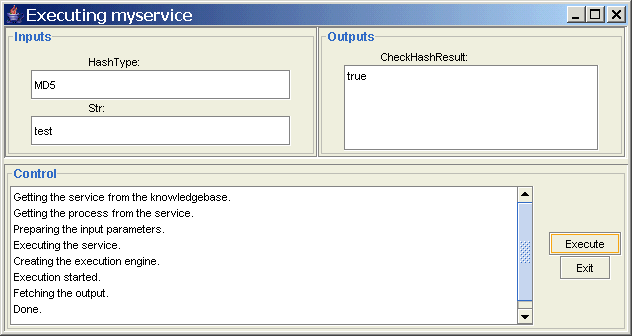
图7 执行组装后的服务
搬家前链接:https://www.cnblogs.com/bjzhanghao/archive/2005/06/12/173302.html