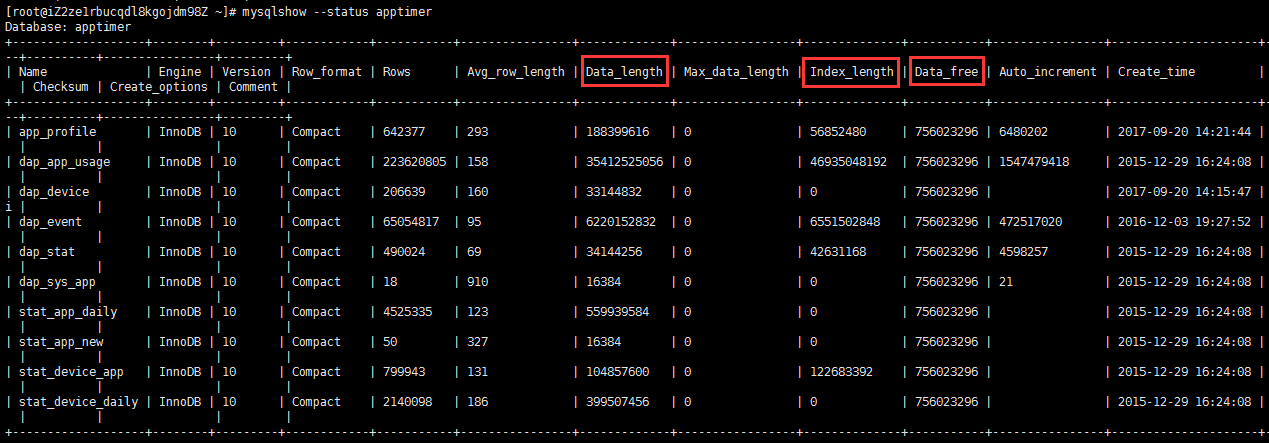
上次使用Amazon EC2的步骤没有记下来,导致这次配置新帐号时比较麻烦,这里把配置云服务器的常用操作记录在一起提高效率。2015/5/19注:最早我使用的是Amazon EC2,后来由于价格和SSD的原因改为使用DigitalOcean的服务,再后来由于国内访问速度原因改为使用阿里云的服务,但一直用CentOS 6.5 64bit的环境,所以很多步骤是相同的。
注册EC2
1、注册amazon aws帐号,需要一张信用卡和一个固定电话,过程不再赘述。此过程中可得到一个.pem文件。
2、进入aws management console,在EC2部分,点击launch instance按钮启动一个ec2 instance。综合价格和国内访问速度,我建议选择US-WEST, Oregon区域。使用cloudping这个在线工具可以实测连接速度。
3、 用puttygen(随putty安装)选择conversions->import key菜单项导入前面获得的.pem文件,然后点击save private key按钮即得到.ppk文件。(参考链接)
接下来是按需要配置instance,这里以免费的AMI为例,先运行“sudo su”进入root身份:
配置基本环境
1、创建用户
> useradd xxx
> passwd xxx
2、设置时区
> cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
不过上面的方式重启后好像会失去效果,建议用下面的方式:
> ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
设置完成后最好重启服务器,否则一些服务(例如crond)日志里仍然使用原来的时区。参考链接
20150318注:还要注意/etc/sysconfig/clock文件(此文件表示硬件时钟使用的时区)里配置的内容,曾经有过一台机器是ZONE="America NewYork",导致tomcat里的时间不正确,改为ZONE=Etc/UTC后解决。
3、设置环境变量
在/etc/profile.d下建立一个.sh文件,内容如下:
my_var=xxx
export my_var
注:阿里云服务器初始化和挂载数据盘的方法见这个链接。
安装和配置MySQL
1、安装:
> yum install mysql mysql-server mysql-libs
数据库文件位于/var/lib/mysql, 配置文件是/etc/my.cnf 。
设置数据库的缺省字符集:在/etc/my.cnf里加入character_set_server=utf8(命令show variables like 'char%';可以查看当前值)。
为了避免8小时自动关闭连接,在my.cnf里的[mysqld]下(注意不要放在[mysqld_safe]下)增加interactive_timeout=288000和wait_timeout=288000(两个必须同时改否则不生效),即把默认8小时改为80小时,一般够用了。
若要修改表格列的编码方式,用下面命令:
alter table 'my_table' modify column 'my_column' varchar(45) character set utf8 not null;
启动MySQL服务:
> service mysqld start
2、创建数据库和导入数据:
先进入mysql命令行:
> mysql -uroot
在mysql命令行下,创建一个空的数据库:
> create database mydatabase;
创建所需用户同时授予权限:
> grant all privileges ON mydatabase.* TO 'username'@'localhost' identified by 'mypassword' with grant option;
> flush privileges;
向新建的数据库里导入所需数据(先退出mysql命令环境回到bash下,输入文件一般由mysqldump命令导出得到):
> mysql -uroot mydatabase < myexportedfile.sql
附导出mysql数据库的命令行:
> mysqldump -uroot -p mydb | gzip > my_dumped_file.sql.gz
若导出时想排除某些个表:
> mysqldump -uroot -p mydb --ignore-table=mydb.table1 --ignore-table=mydb.table2 | gzip > my_dumped_file.sql.gz
另,在mysql命令行里使用select ... into outfile和load data命令也可实现数据的导入导出,示例如下:
SELECT * INTO OUTFILE 'c:/temp/my_file.txt' FROM my_table;
恢复时(注意要加LOCAL关键字,否则会提示Can't get stat of 'xxx'错误,参考链接):
LOAD DATA LOCAL INFILE 'c:/temp/my_file.txt' REPLACE INTO TABLE my_table character set utf8;
3、如果想在浏览器里管理数据,一般使用phpMyAdmin,步骤如下:
创建远程用户admin并授予所有权限:
> GRANT ALL PRIVILEGES ON *.* TO admin@"%" IDENTIFIED BY 'mypassword' WITH GRANT OPTION;
安装phpMyAdmin(需添加额外yum源):
> yum install phpmyadmin
配置ftp服务
这里我们使用vsftp。首先是安装,缺省安装目录在/etc/vsftpd:
> yum install vsftpd
修改配置文件:
> vi /etc/vsftpd/vsftpd.conf
把anonymous_enable=YES改为NO,在文件最后部分加上下面内容(防火墙里要开对应端口范围):
pasv_enable=YES
pasv_min_port=62222
pasv_max_port=63333
以上配置让vsftpd只接受pasv模式的连接,所以ftp客户端需要注意一下相应配置。
有时上传大文件结束时提示timeout错误,文件越大出现概率也越大,调整了与timeout有关的参数后依然无效。暂时的解决方法是将文件分卷压缩,上传先合并(cat xxx.*>yyy)再解压缩。注意,分卷解压缩之前要保持各分卷文件的顺序,我曾遇到一个情况是当分卷多于100个时,因为xxx.z100排在了xxx.z11之前,导致合并后的.zip文件无法解压缩。这时,要手工把xxx.z11改名为xxx.z011,其余文件类似处理,可以用excel等工具批量生成命令行(从z01到z99共99个)。
配置Apache
安装:
> yum install httpd
启动Apache服务:
> service httpd start
设置Apache https
1、先安装mod_ssl模块
> yum install mod_ssl
注意:根据linux环境(mod_ssl环境?)不同,这里至少有两种情况:
a) mod_ssl安装后会在/etc/httpd/conf.d/下生成ssl.conf文件,里面已经有LoadModule语句,所以在httpd.conf里不用重复添加;
b) mod_ssl安装后得到的文件是/apache/conf/httpd-ssl.conf,可能需要在httpd.conf里手动添加LoadModule语句,并添加Include "/apache/conf/httpd-ssl.conf"语句。参考链接
2、创建证书
#生成1024位密钥(至少使用1024否则提示RSA_sign:digest too big for rsa key错误,参考链接)
>openssl genrsa 1024 > server.key
#生成证书请求文件,这一步要按要求回答若干问题并设置一个challenge password
>openssl req -new -key server.key > server.csr
#生成证书,365是有效天数
>openssl req -x509 -days 365 -key server.key -in server.csr > server.crt
3、配置apache支持https
修改ssl.conf(或有些linux版本的httpd-ssl.conf)文件,当然上一步骤里得到的server.key和server.crt文件要先拷贝到对应目录。:
SSLCertificateFile /etc/httpd/conf.d/server.crt
SSLCertificateKeyFile/etc/httpd/conf.d/server.key
最后,在ssl.conf里把DocumentRoot、ServerName按实际修改(和httpd.conf内容相同)。如果与tomcat集成过,记得把JkMount也加上。
配置Tomcat
安装,缺省安装目录在/usr/share/tomcat6:
> yum install tomcat6
提醒一下:如果还没有安装过jdk就启动tomcat,会直接在命令行里报Error Code 4错误,yum安装java-1.7.0-openjdk即可解决。
如果你的webapp里有连接池等资源,需要在/usr/share/tomcat6/conf/server.xml里配置好,以下是一个例子:
<Context path="" docBase="/var/www/html/mywebapp" debug="0" reloadable="true" crossContext="true">
<Resource name="jdbc/myresourcename" auth="Container" type="javax.sql.DataSource"
maxActive="100" maxIdle="30" maxWait="10000"
removeAbandoned="true" removeAbandonedTimeout="60" logAbandoned="true"
username="myusername" password="mypassword" driverClassName="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/mydatabase?characterEncoding=utf8"/>
</Context>
注:linux下使用tomcat6 dbcp会报classnotfound的问题。暂时解决方法:复制tomcat-dbcp.jar到/usr/share/tomcat6/lib。(参考链接)
如果用连接池,还需要把数据库的驱动程序复制到/usr/share/tomcat6/lib下,仅仅在webapp里包含驱动是不行的。
此外,当url里会有中文出现时,在server.xml里的<Connector>标签需要加上URIEncoding="UTF-8"属性。如果是与Apache整合的情况,注意给8009也设置这个属性。
要开启压缩功能,可以按下面的方式设置:
<Connector port="8080" protocol="HTTP/1.1" connectionTimeout="20000"
redirectPort="8443" URIEncoding="UTF-8"
compressableMimeType="text/html,text/xml,text/plain,application/json"
compression="on" compressionMinSize="256" />
另注:若启动tomcat时发现catalina.out里提示UnknownHostException,可修改/etc/hosts文件,把/etc/sysconfig/network里定义的HOSTNAME映射为localhost。
整合apache与tomcat
Apache可以通过jk模块与n个位于相同或不同主机上的tomat实例配合,达到负载均衡的目的,缺省情况下这些tomcat监听8009端口。具体的配置方法如下:
首先在apache网站下载mod_jk(文件名如mod_jk-1.2.31-httpd-2.2.x.so,注意32位与64位有区别), 放到/etc/httpd/modules目录下,并chmod 755,下载地址32位/64位供参考。
进入/etc/httpd/conf目录,创建一个workers.properties文件,内容如下:
workers.tomcat_home=/usr/share/tomcat6
workers.java_home=/usr/lib/jvm/jre
ps=/
worker.list=ajp13
worker.ajp13.port=8009
worker.ajp13.host=localhost
worker.ajp13.type=ajp13
worker.ajp13.lbfactor=1
可参考:The Apache Tomcat Connector - Generic HowTo
编辑/etc/httpd/conf/httpd.conf文件,把下面的内容放在所有LoadModule命令的最后,其中JkMount命令后面的参数根据需要调整:
LoadModule jk_module modules/mod_jk-1.2.31-httpd-2.2.x.so
JkWorkersFile /etc/httpd/conf/workers.properties
JkLogFile "logs/mod_jk.log"
JkLogLevel info
JkMount /*.jsp ajp13
JkMount /*.do ajp13
发布web应用(webapp)时应直接放到apache页面目录下(/var/www/html/mywebapp),而不需要在tomcat/webapps下发布。注意apache不会像tomcat那样自动解压缩.war文件,所以需要手动解压缩,命令是:unzip mywebapp.war -d mywebapp。
要让你的域名能直接访问到这个web应用,有两处需要注意。1)在/etc/httpd/conf/httpd.conf里增加一个VirtualHost,内容见下面代码(DocumentRoot不需要修改);2)在/usr/share/tomcat6/conf/server.xml里该web应用的<context>的path属性应设置为""(不能设置为"/",否则tomcat里request.getContextPath()将返回"/"而非空字符串,可能导致一些URL失效,参考链接)。Update 2010/10/10: 在httpd.conf里还应该指定ServerName为你的域名,否则启动httpd时会提示“无法可靠获取域名”的警告。
<VirtualHost *:80>
DocumentRoot /var/www/html/myapp
ServerName www.mydomain.com
JkMount /* ajp13
</VirtualHost>
配置虚拟主机
Apache里的配置(注意使用ServerAlias使得www.mydomain.cn和mydomain.cn都可访问。“The ServerAlias directive sets the alternate names for a host, for use with name-based virtual hosts. The ServerAlias may include wildcards” 参考链接):
<VirtualHost *:80>
DocumentRoot /var/www/html/myapp
ServerName www.mydomain.cn
ServerAlias mydomain.cn
JkMount /* ajp13
</VirtualHost>
Tomcat里的配置(同样注意Alias的使用。 “A common use case for this scenario is a corporate web site, where it is desireable that users be able to utilize either www.mycompany.com or company.com to access exactly the same content and applications.” 参考链接):
<Host name="www.mydomain.cn" appBase="webapps" unpackWARs="true" autoDeploy="true">
<Alias>mydomain.cn</Alias>
<Context ...>...</Context>
</Host>
配置smtp/pop服务
使用postfix实现smtp,用cyrus实现pop和imap,过程可参考《PostFix安装配置详解》。
需要注意的,cyradm登录时要指定--auth plain
安装Discuz!论坛
这里安装的是Discuz! 7.2版本,方法可参考此链接。 其中可能需要yum install php,php-mysql,php安装以后会自动配置apache的参数(配置文件在conf.d下),重启apache即可。
配置好以后,进入http://hostname/install/index.php即可完成后续配置,包括config.inc.php文件都可以在向导里完成了。
服务器启动时自动启动服务
chkconfig vsftpd on
chkconfig httpd on
...
检查是否已设定成功(完整服务列表在/etc/rc.d/init.d/下)
chkconfig --list
给micro instance增加swap分区
micro版本的虚拟机只分配600m左右的内存,如果无法支持应用所需,可以考虑使用swap分区。
方法参考此链接 ,但是要注意增加swap后,EBS的I/O次数会上升很多,导致额外的费用,经验教训参考此链接。
增加EBS分区
如果EC2的磁盘容量不够用,可以在aws console里创建新的EBS分区,然后挂载到EC2上使用。方法也比较简单见此链接,要注意的是在aws console里attach后,到EC2里别忘了要先mkfs一下才能mount,最好在fstab里设置为自动挂载。
定时启动/停止ec2 instance以节省费用
如果服务器只在白天有人访问,可以让它晚上关闭,这样可以节约大约1/3的费用。
需要在另外一台ec2服务器上设定定时命令,参考这个链接。当然,在停止期间是无法继续对外提供服务的。
注意,在crontab里直接运行ec2-start-instances这样的命令可能因为环境问题而失败,最好把这些命令写成单独的脚本文件,然后在crontab里调用。参考链接
另外注意服务器的时区是否与任务执行的时间匹配。
安装SVN服务
用以下命令安装subversion并在指定目录创建一个repository。
> yum install subversion
> svnadmin create /root/svn/repo1
然后分别修改/root/svn/repo1/conf目录下的svnserve.conf、passwd和authz这三个文件就可以了。具体的配置方法不复杂,可参考这个链接。
启动svn服务:
svnserve -d -r /root/svn
开机自动启动svn服务:编辑start-svn.sh脚本内容如下并添加执行权限(chmod +x):
#!/bin/bash
svnserve -d -r /root/svn
然后在/etc/rc.local文件最后一行增加对start-svn.sh的调用。
注:svn实际是安装在DigitalOcean提供的云主机上,而非amazon的ec2上,环境为CentOS 6.5 x64。
安装pptpd服务(VPN)
可参考这篇帖子,如果连接出现问题,可tail /var/log/messages查看具体原因,然后google解决。
另一篇帖子
使用中遇到的问题和解决
1、instance运行正常但无法访问(ssh, http, ftp)
这种情况应该比较少遇到,forum给的答案是host环境出了些问题,解决方法是强制停止并重启,这时aws会在其他host上部署这个instance,问题也就随之解决。原话引用:
The instance is on a host that is experiencing some issues, at this point the best way to recover your instance would be to perform a force stop (adding --force to ec2-stop-instances command or by using the "force stop" action in ElasticFox) in order to have the instance stopped and be able to start it again on a new host.
2、问题同上
2012/8/14夜间遇到和上面一样的问题,这次的原因是elastic IP被墙。解决方法是不停更换elastic IP并"telnet xxx 22"直到能连接,然后将域名指向新的IP地址。
3、Tomcat吃掉过多VIRT内存的问题
尚未找到解决方案。(网上有不少人问过这个问题,目前的结论是不需要过于担心VIRT的数字,以RES的值为准。)
4、httpd进程占用过多内存
服务器运行一段时间以后,top发现有多个httpd进程并且每个进程都占用不少内存。首先free -m查看实际可用内存还有多少(重点看-/+ buffers/cache这一行的值,Linux Ate My Ram,居然有专门的域名解释这个问题),如果还有很多则不用管,这只是linux管理内存的方式而已。如果确实没有多少可用内存了,试试网上查到的这个解决方法:在httpd.conf里将workers.c模块下的MaxRequestsPerChild值设置为一个较小的值,例如50(缺省为0,表示不限制数量)。参考链接
更新2015/10/21: 今天检查/var/log/httpd/access_log时发现,有大量对/xmlrpc.php的请求,来自三个ip,平均每秒两三次,应该是服务器被利用wordpress的xmlrpc漏洞了(aliyun的云盾没有提示)。

初步先删除wordpress/xmlrpc.php文件解决,稍后看效果是否需要进一步处理。备选方案链接
更新:觉得还是禁止ip的方式更好,方法很简单,在httpd.conf里加下面的语句(apache建议在能修改httpd.conf的情况下不要使用.htaccess方式,会拖慢服务器速度)。
<Directory "/var/www/html/wordpress">
Deny from 159.253.151.106
Deny from 159.253.151.108
Deny from 159.253.151.110
</Directory>