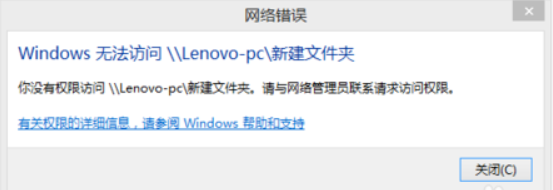
问题:Win7电脑访问Win10电脑的共享文件夹时,提示下面的错误:
解决方法:
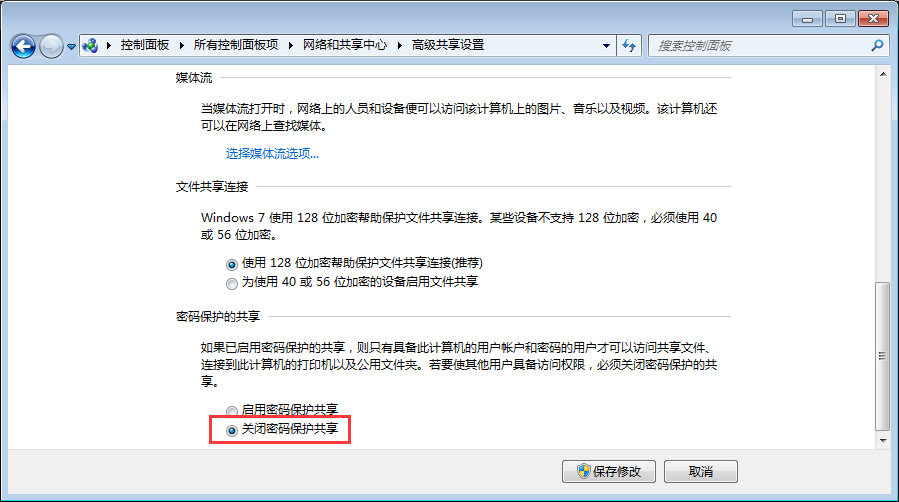
1、在Win10高级共享设置里,勾选“关闭密码保护共享”。这样客户端访问时就不会提示输入用户名密码了(我遇到的情况是即使输入了正确的用户名密码也提示不正确,这个问题并没解决)。
2、在Win10共享的文件夹属性的“安全”页里,加入"Everyone"这个用户并设置足够的权限即可。并不像网上说的那样,需要修改组策略“网络安全:LAN 管理器身份验证级别”。
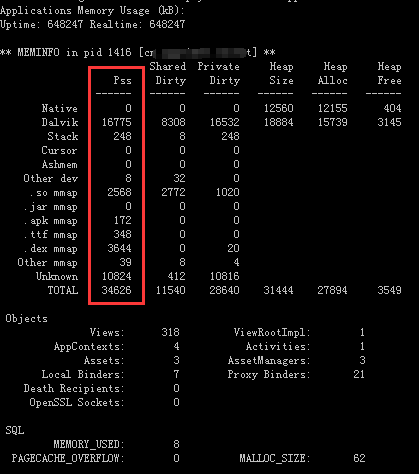
要查看指定app在手机上占用多少运行内存,首先将手机连接到电脑,然后在命令行执行下面的命令(其中com.my.package.name是app的包名):
adb shell dumpsys meminfo com.my.package.name
执行结果通常如下,其中Pss那一列的值(单位:kB)是我们主要需要关注的:
参考链接:
adb shell dumpsys meminfo - What is the meaning of each cell of its output?
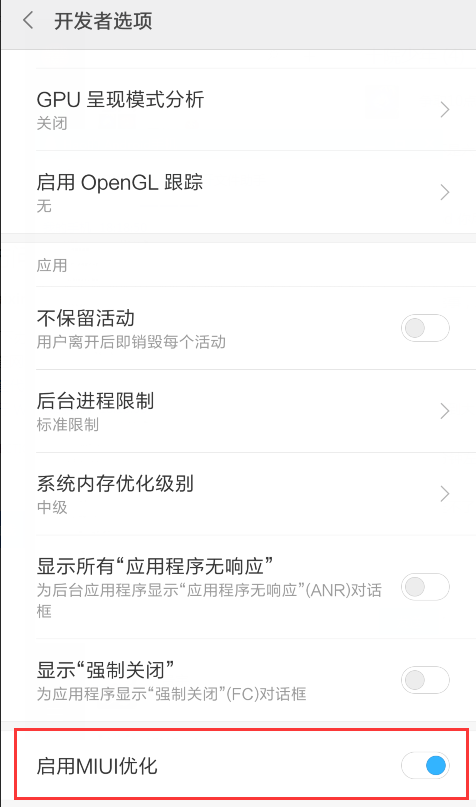
AndroidStudio 2.3,在小米4c搭载miui8真机上运行程序,提示下面的错误信息:
Installation error: INSTALL_CANCELED_BY_USER
在MIUI开发者选项里,关闭“启用MIUI优化”选项。
关闭此选项时被要求重启,重启后暂时没有发现日常使用有什么变化。
Update: 关闭此选项后发现手机发热和耗电明显,应该是对后台应用的拦截失效导致的。
参考链接:
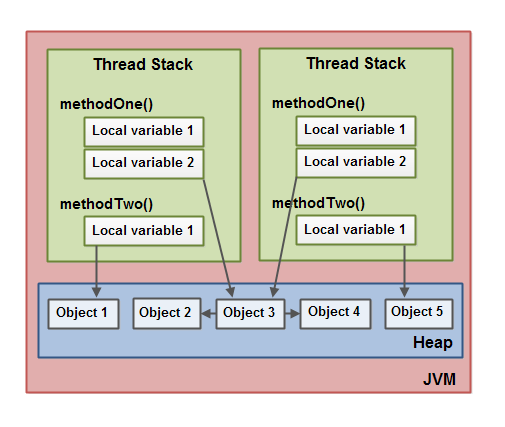
JVM的内存分为堆(heap)和栈(thread stack)两类区域,分别存放不同数据,规则如下。
以下数据存放在heap中:
以下数据存放在stack中(每个线程有自己的thread stack,互相不可见):
参考资料:
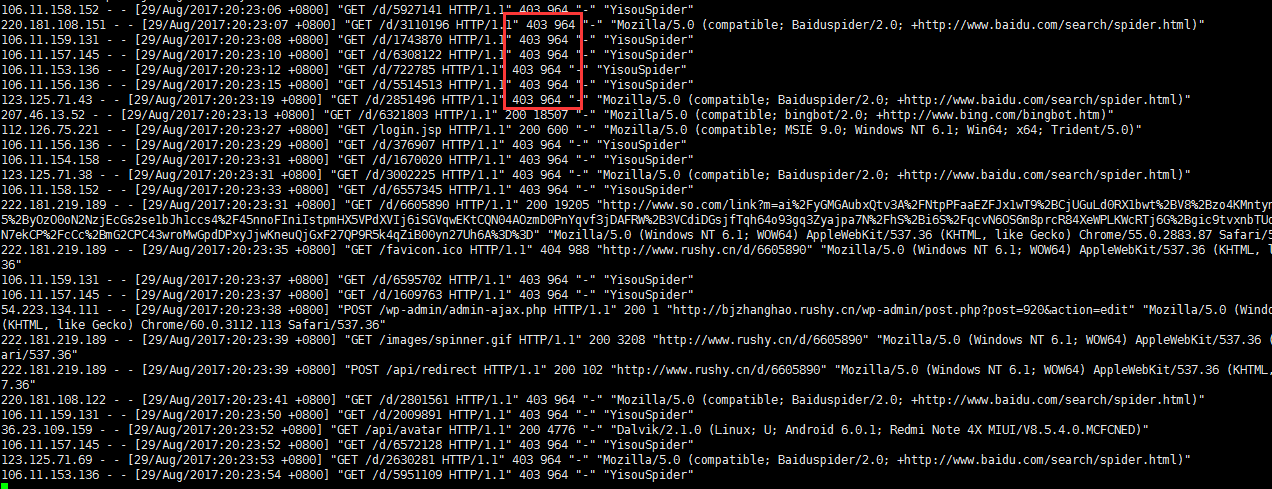
在apache access log里看到很多一搜(现在好像叫“神马搜索”)的爬虫:
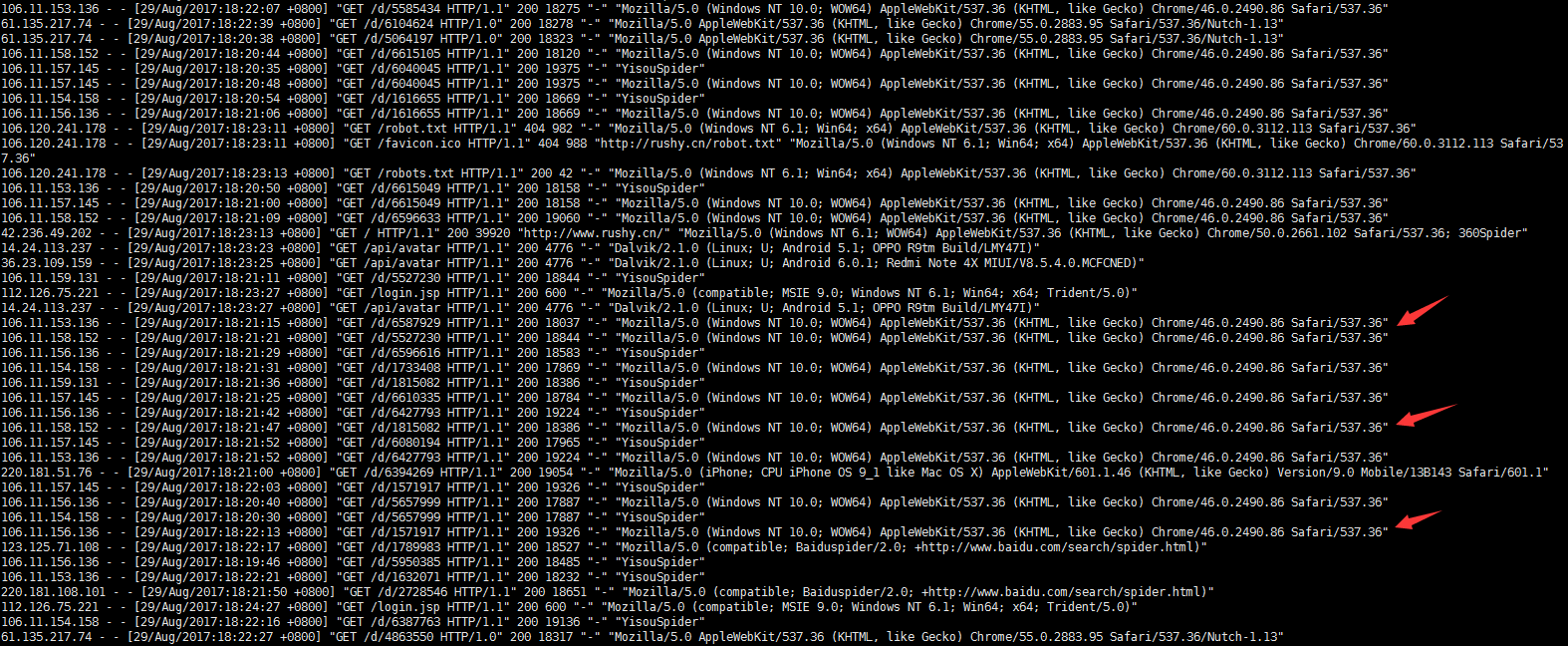
貌似完全不理会robots.txt啊:
User-agent: * Disallow: Crawl-delay: 60
果断在tomcat的server.xml里禁掉IP段:
<Context ...> <!-- 220.181.108.*, 123.125.71.*: baidu spider, 106.11.15*.*: yisou --> <Valve className="org.apache.catalina.valves.RemoteAddrValve" allow="" deny="106.11.15\d.\d+, 220.181.108.\d+, 123.125.71.\d+"/> </Context>
看看效果:
参考资料:
虽然zk本身没有对watch数量设置上限,但在实际场景里,由于watch数量过多导致系统资源被耗尽的情况偶有发生。
以一个实际场景为例,这个场景里有30000个设备,在zk里每个设备对应一个znode,然后有storm的topology对每个znode加上3个watch(通过curator,一个spout两个bolt),这个topology的并发是200。
计算一下总的watch数量就是30000x200x3=1800万个,按照ZOOKEEPER-1177的描述,平均每个watch占用100字节左右内存,1800万个watch大约占用1.8GB内存。这时必须相应调高zk能够使用的内存数量。
在命令行使用 “echo wchs | nc zkaddress port” 命令可以查看当前zk里watch数量,相当于先telnet到zk再发送zk提供的四字命令(完整命令列表):
![]()
根据Cloudera的建议(见:Impala maximum number of partitions),一个impala表最多使用10万个分区(partition),最好不超过1万个分区。
在实际场景里,假设我们想按“设备ID”和“天”对设备数据进行分类,那么当有20000台设备时,每年所需要的分区数量是20000x365=7300000个,已经大大超出了impala的限制,这时就要考虑调整分区粒度,比如从时间维度调整为每个月分一个区,从设备维度调整为将若干个设备分为一组再以组为单位分区。但无论如何,这些调整通常对业务应用是有代价,需要衡量是否能够接受。
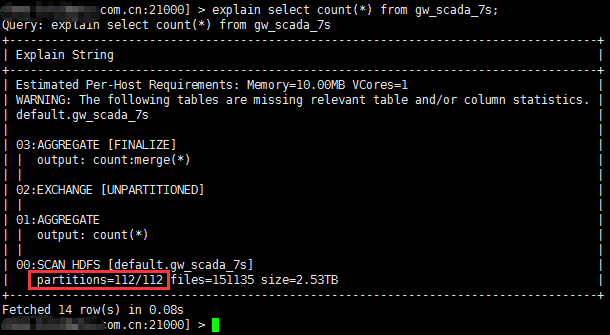
要统计一个表有多少个分区,可以使用explain语句:
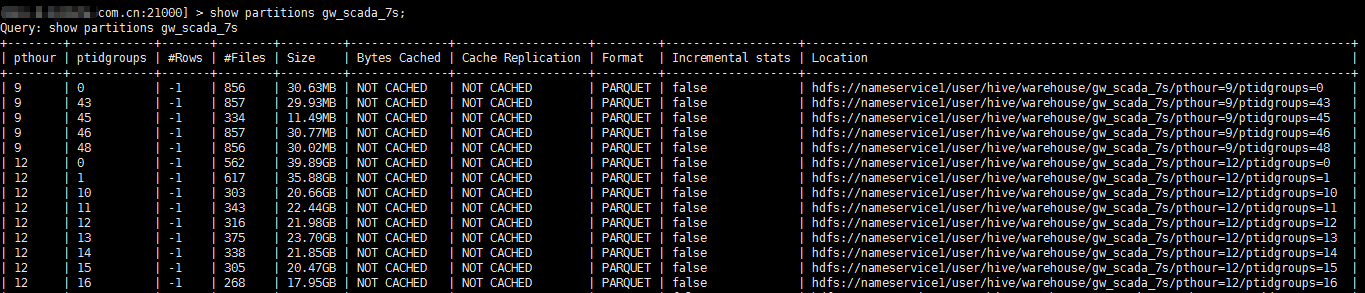
要查看详细分区信息,使用show partitions mytable语句:
(注:经过核实,此问题在通过JDBC且SYNC_DDL时出现,impala-shell里REFRESH通常不会超时)
直接修改HDFS上的文件后,需要使用Impala的REFRESH命令更新Impala元数据。当文件数量过多(例如200万个),REFRESH命令会超时。
解决方法:按Partition依次执行REFRESH命令,只要每个Partition的文件数量不多,就可以实现更新整个表的元数据。
REFRESH [db_name.]table_name [PARTITION (key_col1=val1 [, key_col2=val2...])]
HDFS最著名的限制是namenode单点失效问题。
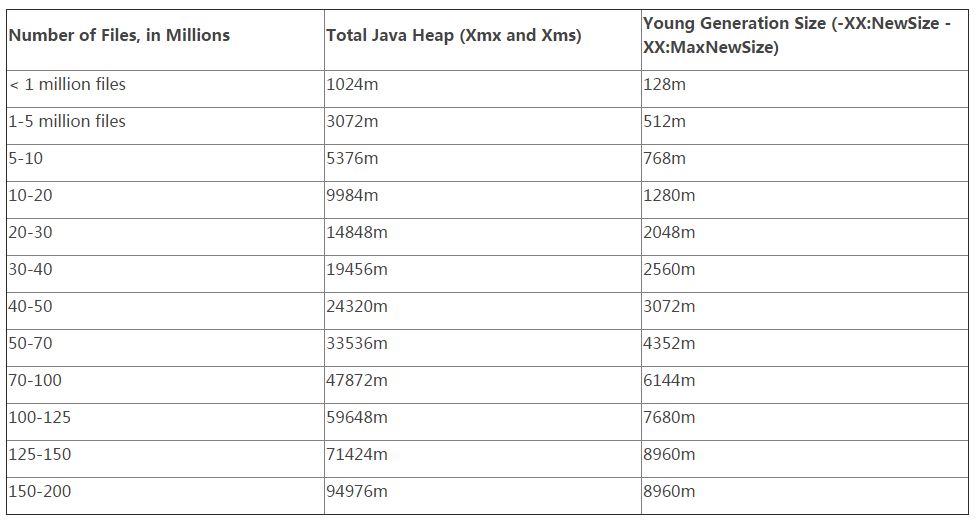
根据cloudera博客文章The Small Files Problem的解释,每个文件、每个目录以及每个块(block)会在namenode节点占用150字节内存,假设有一千万个文件,每个文件一个块,则总共占用20000000*150=3GB物理内存。
仍然以设备数据为例,假设我们想把每个设备的数据按天保存到hdfs文件,那么20000个设备每年产生730万个文件,三年2200万个文件,是硬件资源可以承受的数量级。但如果业务要求对设备的不同类别数据分文件存放,例如设备的高频数据与低频数据,则文件总数量还要乘以数据类型的个数,这时就必须考虑namenode物理内存是否够用。
Hortonworks根据文件数量推荐的namenode内存配置表如下(来源),可以看出1000万文件建议配置5.4GB,比前面估计的值(3GB)稍高,这应该是考虑到namenode服务器额外开销和一定冗余度的数值:
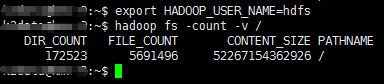
使用“hadoop fs -count /”命令可以统计当前hdfs上已有文件数量,不过这个命令无法看到块的数量。
Parquet是基于列的存储格式,最大优势是从文件中抽取小部分列时效率很高,同时Impala、Hive和Spark等大数据查询/分析引擎都支持它,所以不少大数据系统底层都是用parquet做数据存储。
由于parquet不支持对已有文件的修改,因此在设计系统时就要考虑文件里包含哪些列,就像为数据库设计表结构一样。值得关注的问题是,一个parquet文件里能包含的列数目是有限的,至于上限值是多少与多个因素有关,很难给出一个确切的数字。我查到的一些建议是尽量不要超过1000个列。
例如在PARQUET-222的讨论里,一个例子是假设一个parquet文件有2.6万个整数类型的列,因为每个writer至少需要64KB x 4的内存,写入这样一个parquet文件至少需要6.34GB内存,很容易超出jvm限制。
(三个月前遇到这个问题,当时没有及时记录,现在找资料又花了好几个小时,这次赶紧记下)
参考 PARQUET-222 和 PARQUET-394。
在Cloudera 5.9上安装/更新Spark 2.1.0。
1、下载CSD文件 http://archive.cloudera.com/spark2/csd/,将csd文件(.jar)放在/opt/cloudera/csd目录,并执行命令将文件拥有者修改成cloudera-scm:
chown cloudera-scm:cloudera-scm /opt/cloudera/csd/SPARK2_ON_YARN- 2.1.0.cloudera1.jar
重启 cloudera-scm-server服务:
service cloudera-scm-server restart
然后在CM页面选择Cluster -> Cloudera Managerment Service -> 操作 -> 重启。
2、下载Parcel文件和对应的.sha1文件 http://archive.cloudera.com/spark2/parcels,将下载得到的parcel文件和.sha1文件复制到/opt/cloudera/parcel-repo目录下,并把.sha1文件改名为.sha(否则可能无法识别)
mv SPARK2-2.1.0.cloudera1-1.cdh5.7.0.p0.120904-trusty.parcel.sha1 SPARK2-2.1.0.cloudera1-1.cdh5.7.0.p0.120904-trusty.parcel.sha
3、点击CM界面右上角的parcel按钮,再点击右上角的检查新Parcel按钮
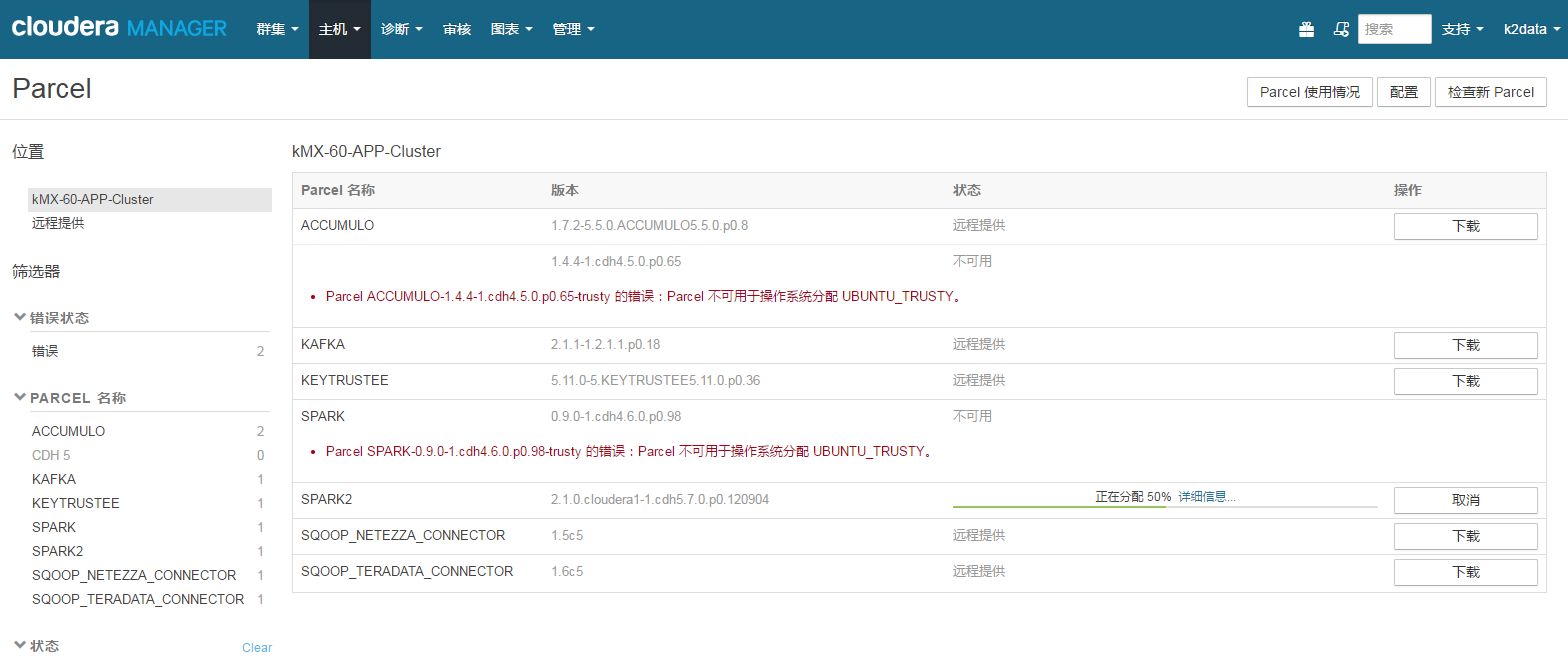
4、选择对应的parcel文件分配和激活(如果是新安装Spark2,在CM页面里选择添加服务 -> Spark 2.0)
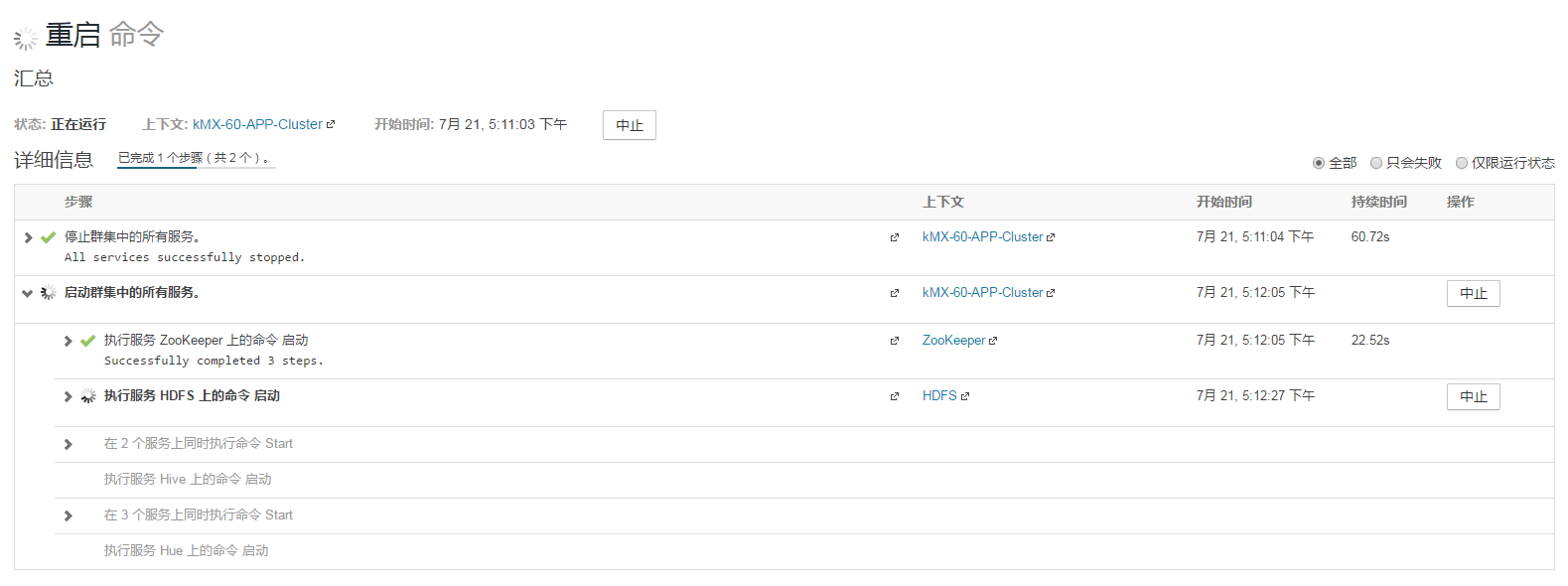
5、按提示重启相关服务
本文介绍Spark的运作原理,并通过在一个实际的Spark运行环境中对数据集进行操作,从而验证这些原理。
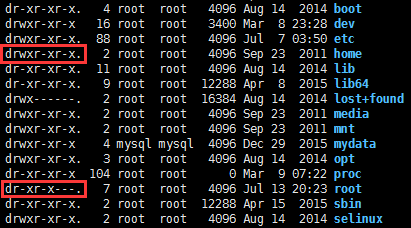
x权限对于目录来说是非常重要的,当用户对某个目录没有x权限时,则不管用户对该目录下的子目录拥有什么样的权限,都将无法对子目录进行任何操作。
通常/root缺省是没有x权限的,因此mysql导出文件(SELECT ... INTO OUTFILE)到/root下的任何目录都会提示无法写入,不论这个目录的owner是谁,也不论这个目录是否777权限:
ERROR 1 (HY000) at line 1: Can't create/write to file '/root/my/out.csv' (Errcode: 13)
而/home缺省是有x权限的,因此在这个目录下mysql用户的文件夹,是可以用于mysql导出到文件的。