记得几年前汉化软件一般是用二进制编辑工具在编译后的文件中查找和替换英文单词,这个过程需要使用很多技巧,非常的麻烦。而现在,在开发时对应用程序进行国际化处理已经越来越成为一个必不可少的步骤了。例如这次我参与的项目是给台湾客户做的,他们要求英文和繁体中文两个版本,幸好我们使用的开发工具是Eclipse,利用它的国际化功能可以很方便的将写在代码里的字符串提出到独立的资源文件中,这里用一个简单的例子说明一下这个过程。
在Eclipse里建立一个名为nls-test的工程(也可以国际化已有工程),新建一个类NLSTest,内容如下:
public class NLSTest {
public NLSTest() {
String str1="Hello world!";
System.out.println(str1);
}
public static void main(String[] args) {
new NLSTest();
}
}
现在,这个类的输出是在代码里写死的,如果要改变就必须修改代码然后重新编译。下面我们利用Eclipse解决这个问题。在导航器(Package Explorer)里右键单击这个文件,选择Source -> Externalize Strings,就会打开一个对话框,在这里列出了该类中尚未国际化的字符串,见下图。
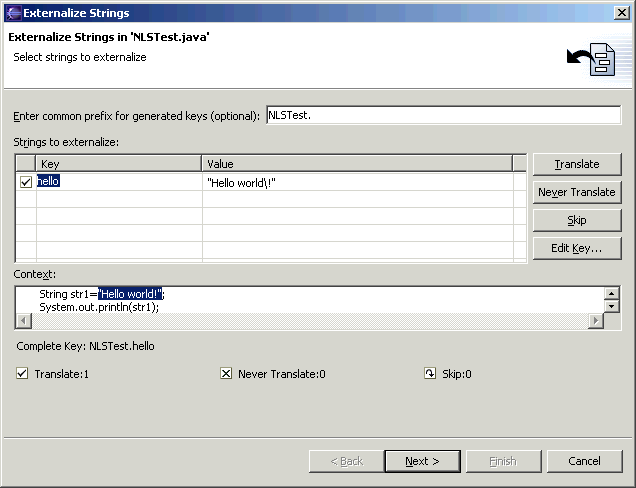
图1 国际化向导第一步
单击每个字符串前面的小方块可以选择对该串 1、进行国际化处理 2、永不进行国际化处理 3、这次不处理。我们选择要对这个字符串进行国际化处理,并把它的Key修改为比较好理解的名称hello,注意在对话框最上方可以指定一个通用的前缀,这个值会加在每个Key前面作为最终写在资源文件(扩展名是.properties)里的Key名称。好,按下一步继续。
在这里要指定properties文件的名称,如果需要的话要指定一个用于从properties文件中取资源的类,一般是XXXMessages的格式,再按下一步,会显示一个所作更改的确认列表,确认后按Finish按钮完成向导。
可以看到Eclipse为我们生成了NLSTestMessages.java和NLSTest.properties,打开后者会看到里面只有这么一句:
NLSTest.hello=Hello world!
而前者NLSTestMessages的作用是根据参数Key从后者取对应的字符串值,看一看现在的NLSTest.java就知道了,它的内容现在是这样的(只列出构造方法,main方法同上):
public NLSTest() {
String str1=NLSTestMessages.getString("NLSTest.hello"); //$NON-NLS-1$
System.out.println(str1);
}
后面的注释是Eclipse自己用的,标有这个注释的字符串在国际化将被忽略。注释中的数字1表示要忽略的是该行中第一个字符串,如果一行语句里有多个字符串被忽略,将会有多个这样的注释,但数字会各不相同,像这样:
//$NON-NLS-1$ //$NON-NLS-2$ //$NON-NLS-3$
好了,现在这个类的国际化处理就算完成了。要想让这个类可以根据用户所在地区输出不同语言的结果,可以在NLSTest.properties同一目录下创建名为NLSTest_XX.properties的文件,其中XX表示国家名称,例如中国是zh_CN或zh_TW,法国是FR等等。新创建的文件里也要有和原来文件相同的名值对,但值是不同语言的,NLSTestMessages类会根据用户机器的地区设置值自动从不同的资源文件里取值,这样就达到了国际化的目的。要在自己的机器上测试运行结果,可以在Eclipse的运行设置里面加上这样的参数:-nl zh_TW,这样就不用费力气设置区域了。(2012/5/4更新:此方法可能有误,在Eclipse3.6里是启动程序时在VM arguments里加上-Duser.language=XXX即可以所需要的语言环境启动程序)
国际化的原理很简单,Eclipse提供的这个功能使国际化变得更容易了。不过关于国际化还有一些细节问题,包括对含参数资源的处理,字符编码处理等等,下篇将对它们进行讨论。
搬家前链接:https://www.cnblogs.com/bjzhanghao/archive/2004/08/08/31262.html